
后端开发四种层式结构
- B树 / B+树:关系型数据库核心存储结构(mysql、mogodb)
- 时间轮:海量定时任务检测(linux、skynet、kafka)
- 跳表:高并发有序存储(lucune、redis、rocksdb)
- LSM-Tree:更高性能以及更高空间利用率的数据存储结构(rocksdb)
一、B树和B+树
MySQL数据库的索引的数据结构主要是Hash表或B+树.
先引入问题, 数据库索引为什么使用树结构存储?
因为树的查询效率高, 而且可以保持有序. 二叉树的时间复杂度是O(logN), 查找和比较次数都是最小的, 但是并没有使用二叉树作为索引的数据结构.
没有使用二叉树的原因是因为磁盘IO, 数据库引擎是存储在磁盘上的, 当数据量比较大的时候, 索引的大小可能有几个G甚至更多. 当我们利用索引查询的时候, 不可能将整个索引全部加载到内存中去, 只能逐一加载每一个磁盘页, 这里的磁盘页对应的索引树的节点.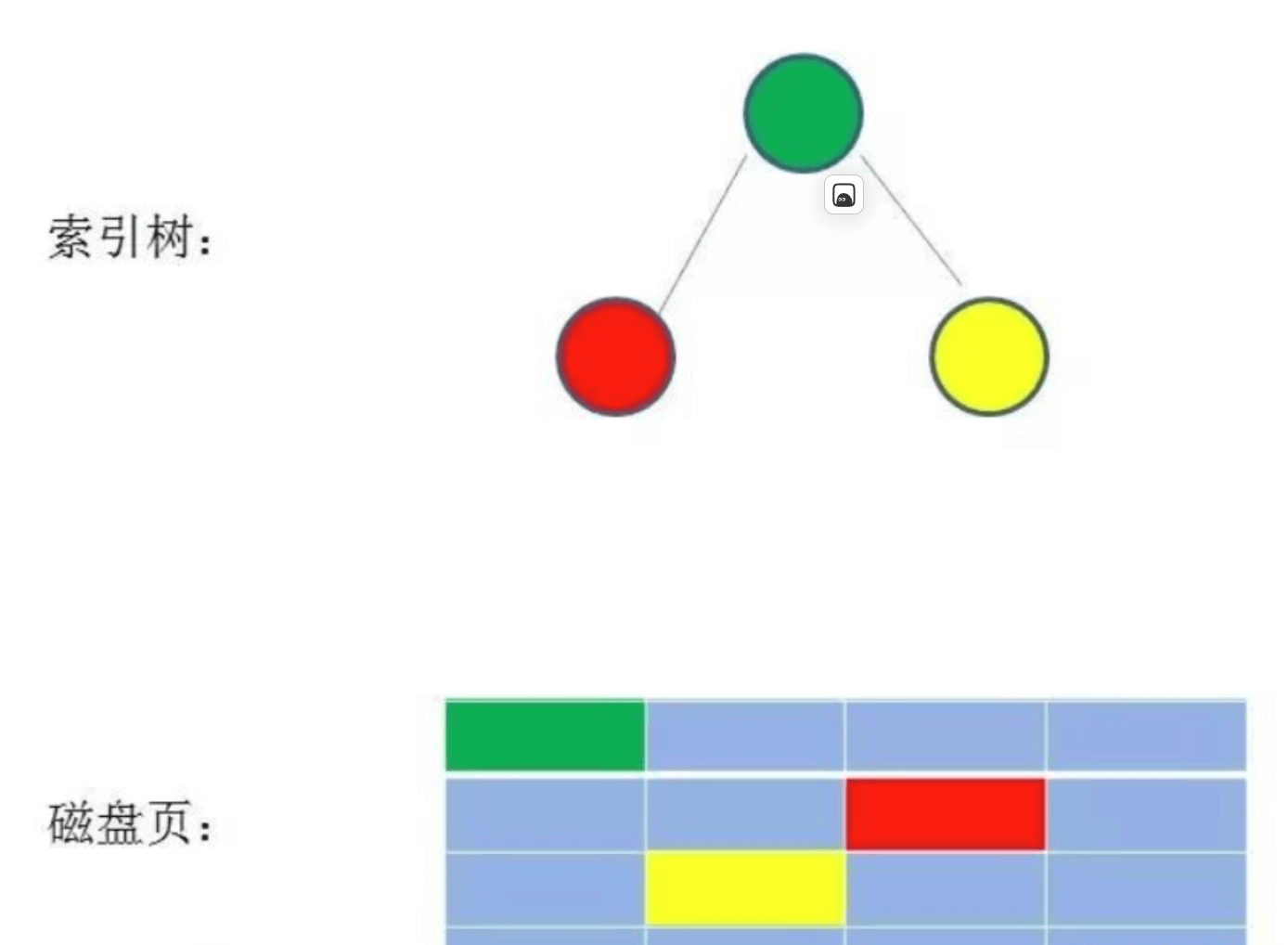
B树
在计算机科学中,B树是一种自平衡的树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数量级的时间复杂度内完成。B树,其实是一颗特殊的二叉查找树(binary search tree),可以拥有多于2个子节点。与自平衡二叉查找树不同,B树为系统大块数据的读写操作做了优化。B树减少定位记录时所经历的中间过程,从而加快存取速度,其实B树主要解决的就是数据IO的问题。B树这种数据结构可以用来描述外部存储。这种数据结构常被应用在数据库和文件系统的实现上。
B树特性
这里的B树,也就是英文中的B-Tree,一个 m 阶的B树满足以下条件:
`每个结点至多拥有m棵子树;
`根结点至少拥有两颗子树(存在子树的情况下),根结点至少有一个关键字;
`除了根结点以外,其余每个分支结点至少拥有 m/2 棵子树;
`所有的叶结点都在同一层上,B树的叶子结点可以看成是一种外部节点,不包含任何信息;
`有 k 棵子树的分支结点则存在 k-1 个关键码,关键码按照递增次序进行排列;
`关键字数量需要满足ceil(m/2)-1 <= n <= m-1;
典型的B树(4阶)如下图所示: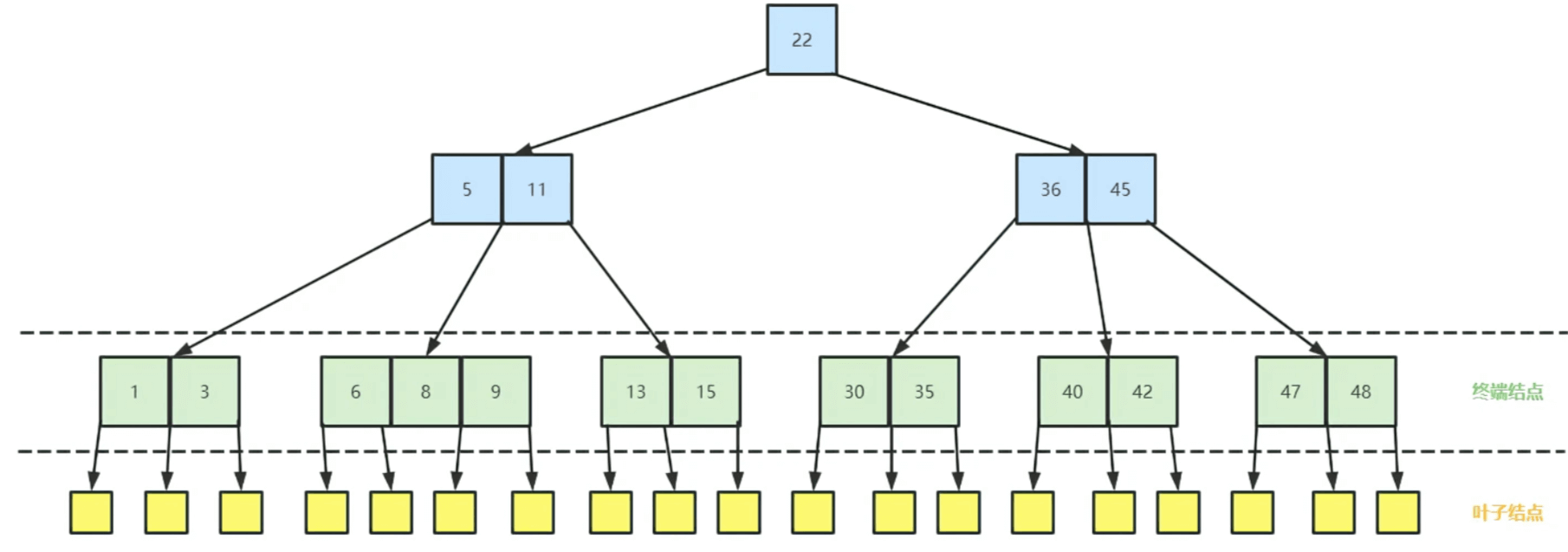
为什么要B树
磁盘中有两个机械运动的部分,分别是盘片旋转和磁臂移动。盘片旋转就是我们市面上所提到的多少转每分钟,而磁盘移动则是在盘片旋转到指定位置以后,移动磁臂后开始进行数据的读写。那么这就存在一个定位到磁盘中的块的过程,而定位是磁盘的存取中花费时间比较大的一块,毕竟机械运动花费的时候要远远大于电子运动的时间。当大规模数据存储到磁盘中的时候,显然定位是一个非常花费时间的过程,但是我们可以通过B树进行优化,提高磁盘读取时定位的效率。
为什么B类树可以进行优化呢?我们可以根据B类树的特点,构造一个多阶的B类树,然后在尽量多的在结点上存储相关的信息,保证层数尽量的少,在B树中可以检查多个子结点,由于在一棵树中检查任意一个结点都需要一次磁盘访问,所以B树避免了大量的磁盘访问;而且B类树是平衡树,每个结点到叶子结点的高度都是相同,这也保证了每个查询是稳定的,查询的时间复杂度是O(log2N)。
总的来说就是利用平衡树的优势,保证了查询的稳定性和加快了查询的速度。
B树的操作
既然是树,那么必不可少的操作就是插入和删除,这也是B树和其它数据结构不同的地方,当然了,还有必不可少的搜索,分享一个对B树的操作进行可视化的网址,它是由usfca提供的。
假定对高度为h的m阶B树进行操作。
插入
通过搜索找到对应的结点进行插入,那么根据即将插入的结点的数量又分为下面几种情况。
如果该结点的关键字个数没有到达到m-1个,那么直接插入即可;
如果该结点的关键字个数已经到达了m-1个,那么根据B树的性质显然无法满足,需要将其进行分裂。分裂的规则是该结点分成两半,将中间的关键字进行提升,加入到父亲结点中,但是这又可能存在父亲结点也满员的情况,则不得不向上进行回溯,甚至是要对根结点进行分裂,那么整棵树都加了一层。
例子如下
将元素7插入下图中的B树
步骤一:自顶向下查找元素7应该在的位置,即在6和8之间
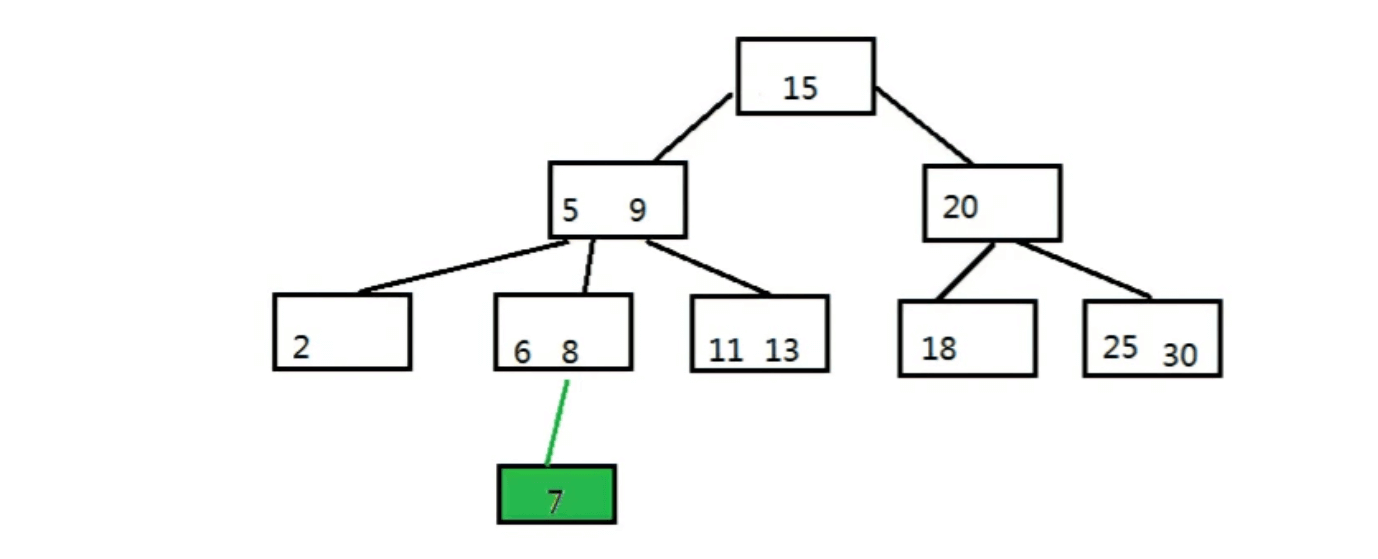
步骤二:三阶B树中的节点最多有两个元素,把6 7 8里面的中间元素上移(中间元素上移是插入操作的关键)
步骤三:上移之后,上一层节点元素也超载了,5 7 9中间元素上移,现在根节点变为了 7 15
步骤四:要对B树进行调整,使其满足B树的特性,最终如下图
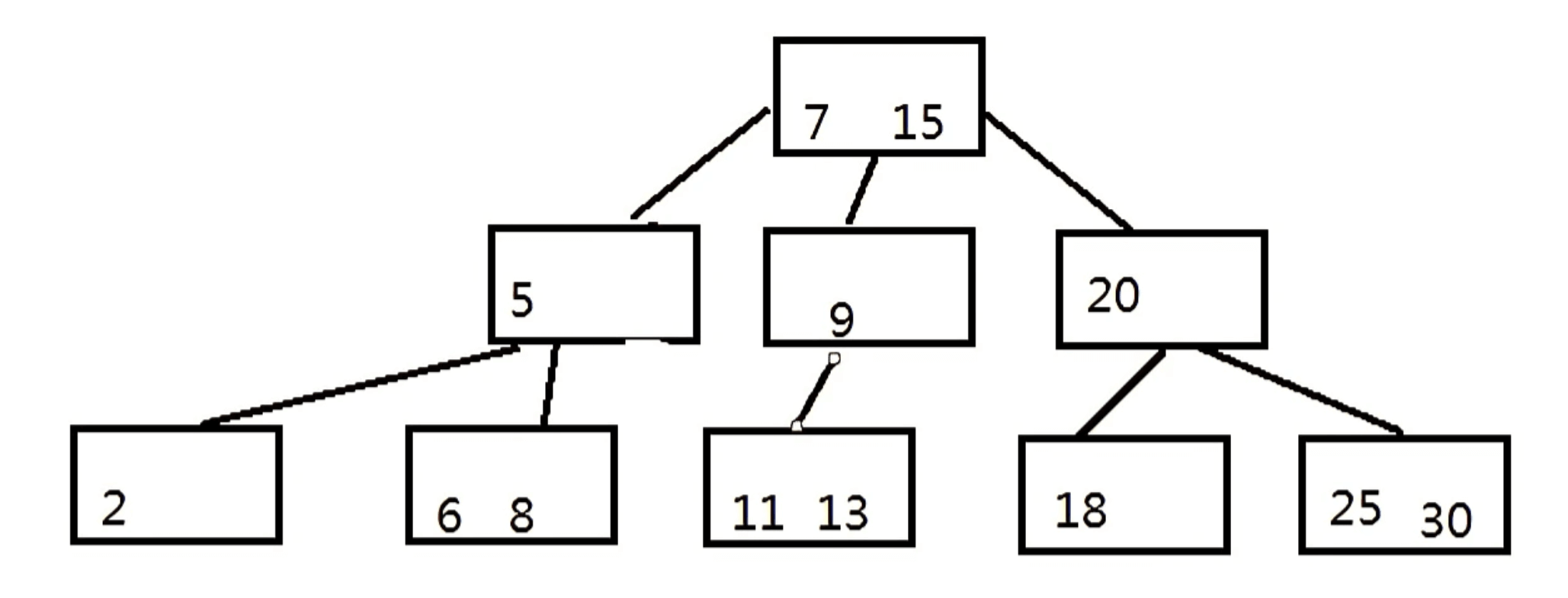
下面是往B树中依次插入
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
删除
B树的删除相对于插入来说较为复杂。
删除分为两种情况:
删除的是非终端结点删除的是终端结点
当我们删除的是非终端结点时,将用该结点的直接前驱或直接后继代替其位置,因此对于非终端结点的删除最后还是转化到了对终端结点的删除。(关键字左子树的最右下结点为直接前驱,右子树的最左下结点为直接后继)
因此我们主要还是讨论对终端结点的删除。
对于终端结点的删除我们又分为了几种情况:
删除后结点的关键字个数未低于下限
直接删除即可
删除后结点的关键字个数低于下限
该种情况下还需要分为以下三种情况
(1). 右兄弟有足够的关键字
有足够关键字的意思就是借给自己一个关键字后还能够保证B树的性质,即关键字个数大于[m/2⌉-1]个。
此时右兄弟的最左关键字上浮到父亲结点,而原来的父亲元素则下沉到被删除关键字的结点中。如下图所示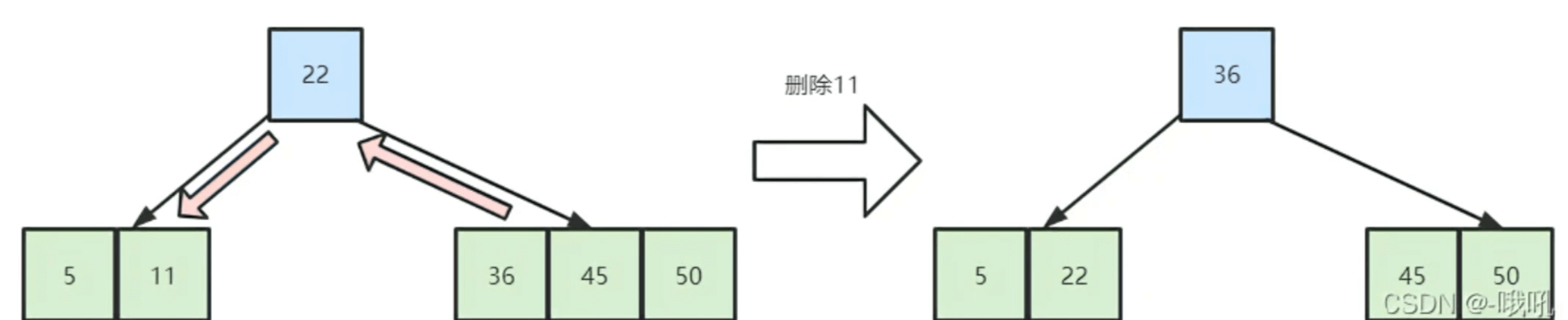
(2). 右兄弟没有足够的关键字,左兄弟有足够的关键字
此时左兄弟的最右关键字上浮到父亲结点,而原来的父亲元素则下沉到被删除关键字的结点中。如下图所示
(3) 左右兄弟都没有足够关键字
此时由于左右兄弟的结点都只有[m/2]-1个,因此,当关键字删除后,该结点与任意兄弟结点的关键字个数的总和必然不大于一个结点所能容纳的上限。
举个例子,对于一个5阶B树来说,每个结点最多有4个关键字,最少要有2个关键字,当该B树删除结点时符合本条情况时,左右兄弟必然都只有2个关键字,而被删除关键字的结点由于删除后自身结点不足,则只剩下1个关键字,因此该结点删除后与任一兄弟的合并都只有3个关键字,完全符合B树性质。
合并过程中,合并的两个结点的父关键字则会下沉,与这个两个合并结点一起合并。具体如下图所示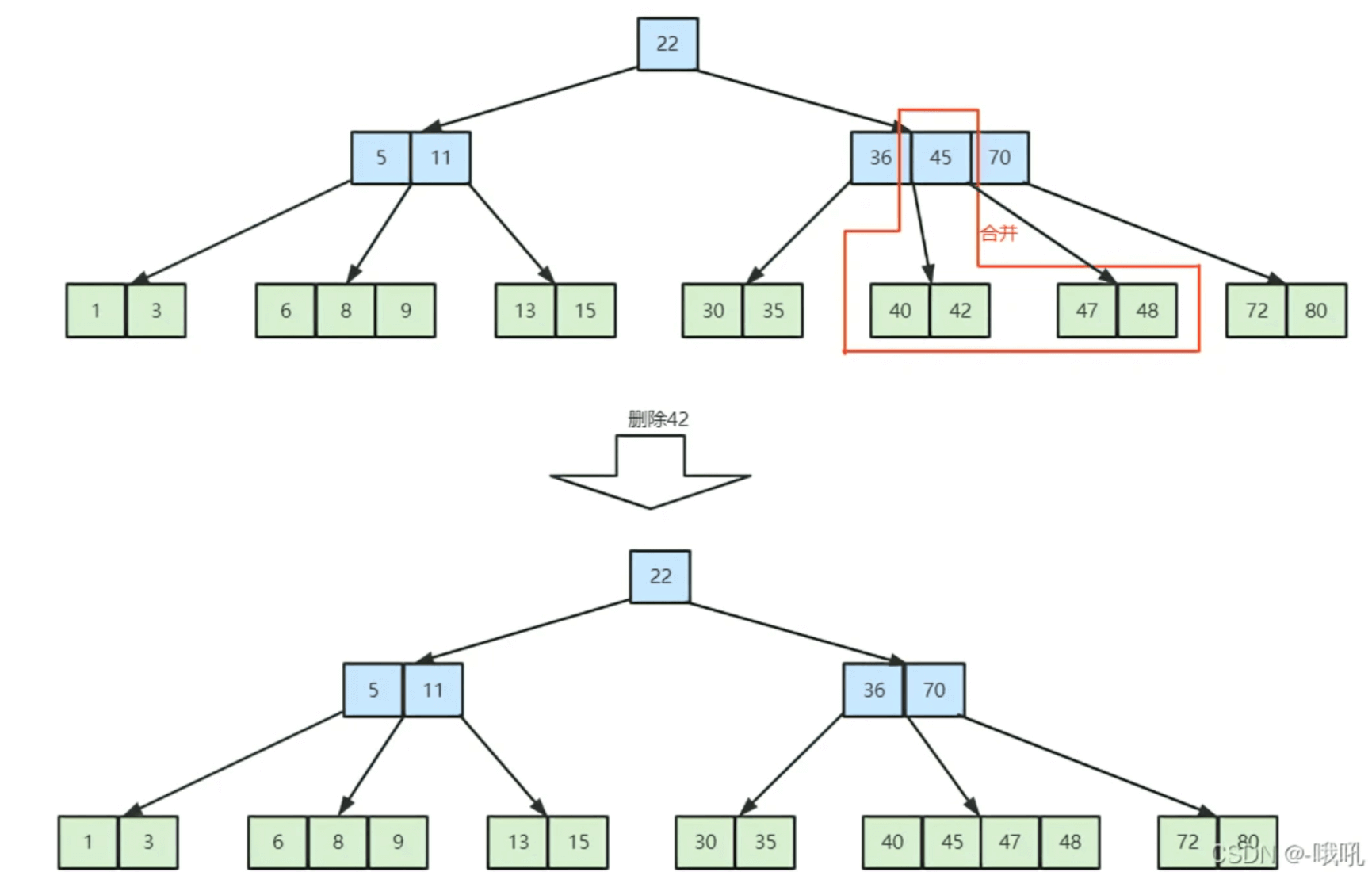
在合并过程中,双亲结点中的关键字会减1.若其双亲结点是根节点,且个数少至0,则直接删除根结点,合并后的新结点成为根。
若双亲结点不是根结点,且关键字数量少于[m/2]-1个,则又要重复之前的步骤进行调整,直至符合B树所有条件。
B+树
我们的B树可以拥有非常高效率的查找速度,那么为什么我们还会需要B+树这个数据结构呢?
事实上,B树的查找效率虽然非常优秀,但是它也有一个自身的缺陷。我们都知道,数据库中的数据都是按照记录存放的,每条记录都是由多个数据项组成。因此我们的每条数据记录通常也不会太短,甚至可能非常之长。同样,如果将这些数据记录按照我们的B树进行组织,那么每个结点将存储的内容就是记录本身,B树是将记录本身作为单位存放的。比如我们用一个5阶B树组织在校学生的数据记录,那么我们每个结点都至少存储2条学生记录。这样乍一看好像没什么问题,但是在检索过程中,由于每个结点所占据的存储很大,我们实际的检索速度很难像前面展示的那些B树一样实现快速的检索(前面的树中每个结点的数据记录都是关键字本身,非常小)。
因此我们引入了B+树,B+树的特殊之处在于它将我们的记录的内容放在了叶子结点上,其他分支节点和终端结点只存放关键字。同时所有的结点的关键字都会再次出现在该关键字对应的子结点上即所有的关键字都会出现在终端结点上,这样保证了每个叶子结点上的数据记录都能够有一个关键字于其对应。在这样的调整下我们每个结点只需要存放记录对应关键字,由此相较于B树,在同样大小的结点约束下,我们的B+树的每个结点可以存放更多的关键字,从而大幅降低我们的树高,提升检索速度。
且在B树的基础上将从m个关键字对应m+1个分支变成了m个关键字对应m个分支,即B+树的结点最大关键字数与B+数的阶相同.
B+树的基本性质
一棵m阶的B+树需要满足下列条件:
- 每个分支结点最多有m棵树和m个关键字
- 根结点至少两棵子树,其他每个分支结点至少有[m/2]棵子树
- 结点的子树个数与关键字个数相等
- 每个关键字都应该出现在其对应子结点中,且每个结点都按照从小到大的顺序排列
- 所有终端结点包含全部关键字及指向相应记录的指针。同时终端结点将关键字从
小到大顺序排列,并且相终端结点按大小顺序相互链接起来。 - 同样是是绝对平衡的
其树形(4阶B+树)如下图所示
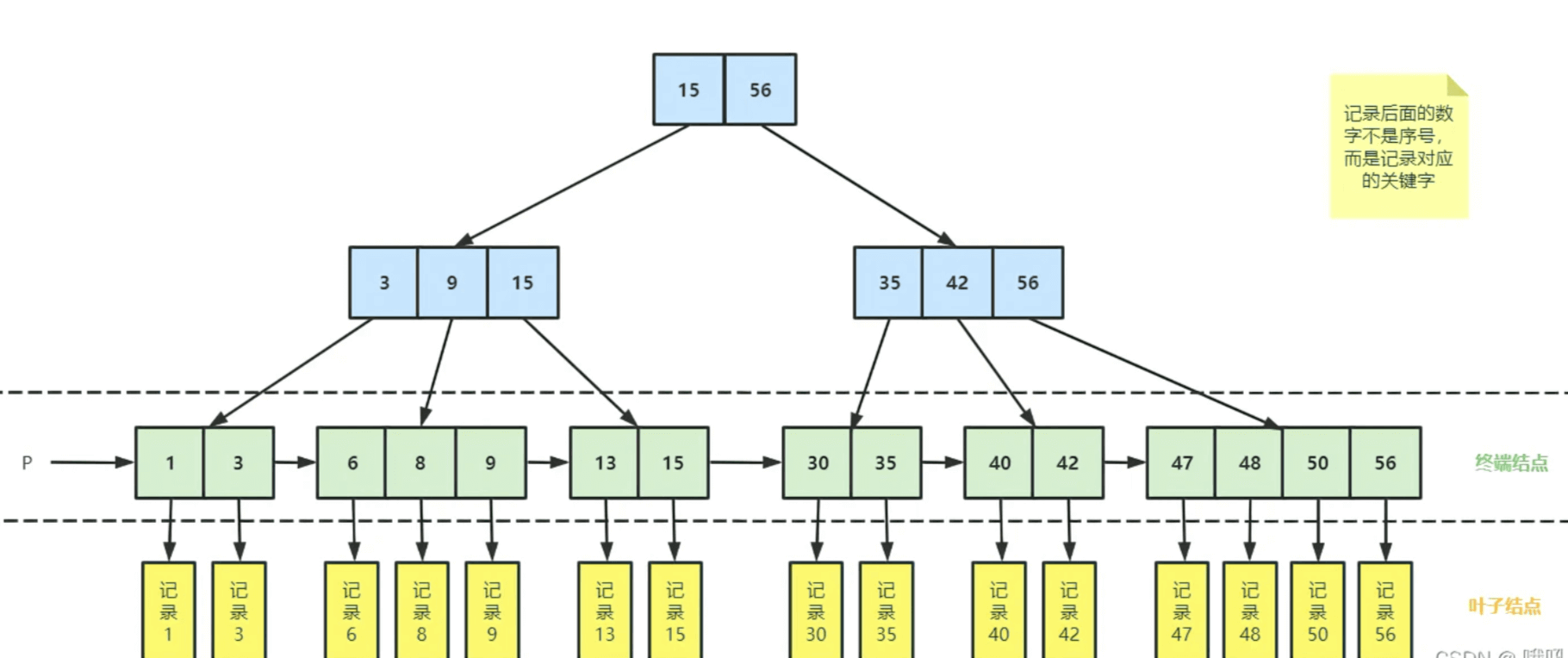

B+树的优势
B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
操作
其操作和B树的操作是类似的,不过需要注意的是,在增加值的时候,如果存在满员的情况,将选择结点中的值作为新的索引,还有在删除值的时候,索引中的关键字并不会删除,也不会存在父亲结点的关键字下沉的情况,因为那只是索引。
B树和B+树的区别
这都是由于B+树和B树具有不同的存储结构所造成的区别,以一个m阶树为例。
关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,虽然B树也有m个子结点,但是其只拥有m-1个关键字。
存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
分支结点的构造不同;B+树的分支结点存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
查询不同;B树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径,其高度是相同的,相对来说更加的稳定;
区间访问:B+树的叶子结点会按照顺序建立起链状指针,可以进行区间访问;
B+树的优势
B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
打个比方:B+树就有点像我们的目录,是索引的一个形式。若一个目录中,除了每个章节的名称外还需包含每章的大致内容,那么本来一页就可以看完的目录就会变成很多也,这并不方便我们从中去找到我们所需要的内容。
B树的优势
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
`但是不可否认,B树依旧是一种优秀的算法
两者的细节对比
| - | m阶B树 | m阶B+树 |
|---|---|---|
| 类比 | 二叉查找树的进化→m叉查找树 | 分块查找的进化→多级分块查找 |
| 关键字和分叉 | n个关键字对应n+1个分叉 | n个关键字对应n个分叉 |
| 结点包含的信息 | 所有结点都包含记录本身 | 分支结点只放关键字,只有终端结点会存放指向记录的指针 |
| 查找方式 | 不支持顺序查找。且查找速度不稳定,可能停留在任何一层 | 支持顺序查找,且查找速度稳定,每次查找都会到达最下层 |
| 平衡 | 绝对平衡 | 绝对平衡 |
| 结点最少关键字数 | ⌈m/2⌉-1 | ⌈m/2⌉ |
B树与B+树在实际代码中的应用
在我们的MySql数据库中我们经常能够看见数据库引擎这个词,而数据库引擎的选择就决定了我们数据库记录的组织和查找方式。我们最常使用的就是我们的MyISAM和InnoDB两个数据库引擎。事实上,这两种数据库引擎所用的都是B+树,但是又有所不同,属于B+树的变体,这个要另外去理解。
而我们的B树呢则是在MongoDB中被使用到了
原文链接:https://blog.csdn.net/qq_33905217/article/details/121827393
二、时间轮
从定时任务说起
自然界中定时任务无处不在,太阳每天东升西落,候鸟的迁徙,树木的年轮,人们每天按时上班,每个月按时发工资、交房租,四季轮换,潮涨潮落,等等,从某种意义上说,都可以认为是定时任务。
大概很少有人想过,这些“定时”是怎样做到的。当然,计算机领域的同学们可能对此比较熟悉,毕竟工作中的定时任务也是无处不在的:每天凌晨更新一波数据库,每天9点发一波邮件,每隔10秒钟抢一次火车票。。。
至于怎么实现的?很简单啊,操作系统的crontab,spring框架的quartz,实在不行Java自带的ScheduledThreadPool都可以很方便的做到定时任务的管理调度。
当你熟练的敲下“* * 9 * * ?”等着神奇的事情发生时,你是否想过背后的“玄机”?
时间轮算法的应用非常广泛,在 Dubbo、Netty、Kafka、ZooKeeper、Quartz 的组件中都有时间轮思想的应用,甚至在 Linux 内核中都有用到。
初识时间轮
业务需要实现一个时间调度的工具,定时生成报表,于是想了一个取巧的办法:
1. 启动时从DB读取cron表达式解析,算出该任务下次执行的时间。
2. 下次执行的时间 - 当前时间 = 时间差。
3. 向ScheduleThreadPool线程池中提交一个延迟上面算出来的时间差的执行的任务。
4. 任务执行时,算一下这个任务下次执行的时间,算时间差,提交到线程池。
5. 当任务需要取消时,直接调用线程池返回的Future对象的cancel()方法就行了。
绝对时间和相对时间
定时任务一般有两种:
1. 约定一段时间后执行。
2. 约定某个时间点执行。
聪明的你会很快发现,这两者之间可以相互转换,比如给你个任务,要求12点执行,你看了一眼时间,发现现在是9点钟,那么你可以认为这个任务三个小时候执行。
同样的,给你个任务让你3个小时后执行,你看了一眼现在是9点钟,那么你当然可以认为这个任务12点钟执行。
我们先来考虑一个简单的情况,你接到三个任务A、B、C(都转换成绝对时间),分别需要再3点钟,4点钟和9点钟执行,正当百思不得其解时,不经意间你瞅了一眼墙上的钟表,瞬间来了灵感,如醍醐灌顶,茅塞顿开: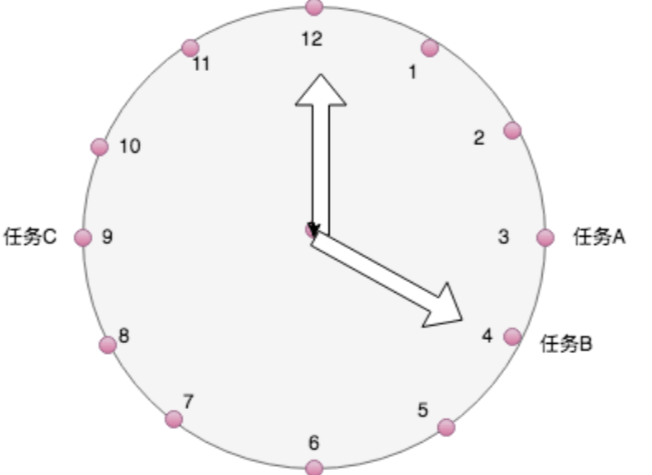
如上图中所示,我只需要把任务放到它需要被执行的时刻,然后等着时针转到这个时刻时,取出该时刻放置的任务,执行就可以了。 这就是时间轮算法最核心的思想了。 什么?时针怎么转? while-true-sleep 下面让我们一点一点增加复杂度。
需要重复执行多次的任务 多数定时任务是需要重复执行,比如每天上午9点执行生成报表的任务。对于重复执行的任务,其实我们需要关心的只是下次执行时间,并不关心这个任务需要循环多少次,还是那每天上午9点的这个任务来说。
- 比如现在是下午4点钟,我把这个任务加入到时间轮,并设定当时针转到明天上午九点(该任务下次执行的时间)时执行。
- 时间来到了第二天上午九点,时间轮也转到了9点钟的位置,发现该位置有一个生成报表的任务,拿出来执行。
- 同时时间轮发现这是一个循环执行的任务,于是把该任务重新放回到9点钟的位置。
- 重复步骤2和步骤3。
如果哪一天这个任务不需要再执行了,那么直接通知时间轮,找到这个任务的位置删除掉就可以了。 由上面的过程我们可以看到,时间轮至少需要提供4个功能:
- 加入任务
- 执行任务
- 删除任务
- 沿着时间刻度前进
上面说的是同一个时刻只有一个任务需要执行的情况,更通用的情况显然是同一时刻可能需要执行多个任务,比如每天上午九点除了生成报表之外,还需要执行发送邮件的任务,需要执行创建文件的任务,还需执行数据分析的任务等等,于是你刚才可能就比较好奇的时间轮的数据结构到现在可能更加好奇了,那我们先来说说时间轮的数据结构吧。
时间轮的数据结构
首先,时钟可以用数组或者循环链表表示,这个每个时钟的刻度就是一个槽,槽用来存放该刻度需要执行的任务,如果有多个任务需要执行呢?每个槽里面放一个链表就可以了,就像下面图中这样: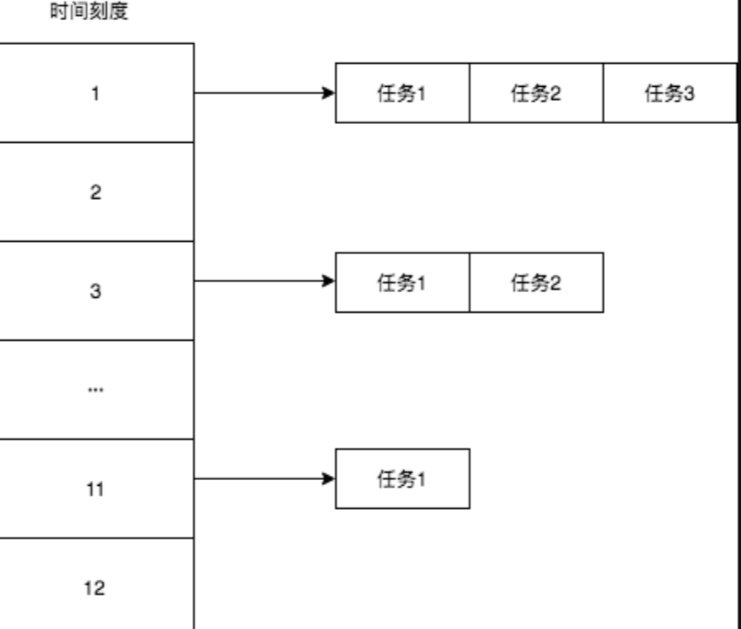
同一时刻存在多个任务时,只要把该刻度对应的链表全部遍历一遍,执行(扔到线程池中异步执行)其中的任务即可。
时间刻度不够用怎么办?
如果任务不只限定在一天之内呢?比如我有个任务,需要每周一上午九点执行,我还有另一个任务,需要每周三的上午九点执行。一种很容易想到的解决办法是:
增大时间轮的刻度
一天24个小时,一周168个小时,为了解决上面的问题,我可以把时间轮的刻度(槽)从12个增加到168个,比如现在是星期二上午10点钟,那么下周一上午九点就是时间轮的第9个刻度,这周三上午九点就是时间轮的第57个刻度,示意图如下: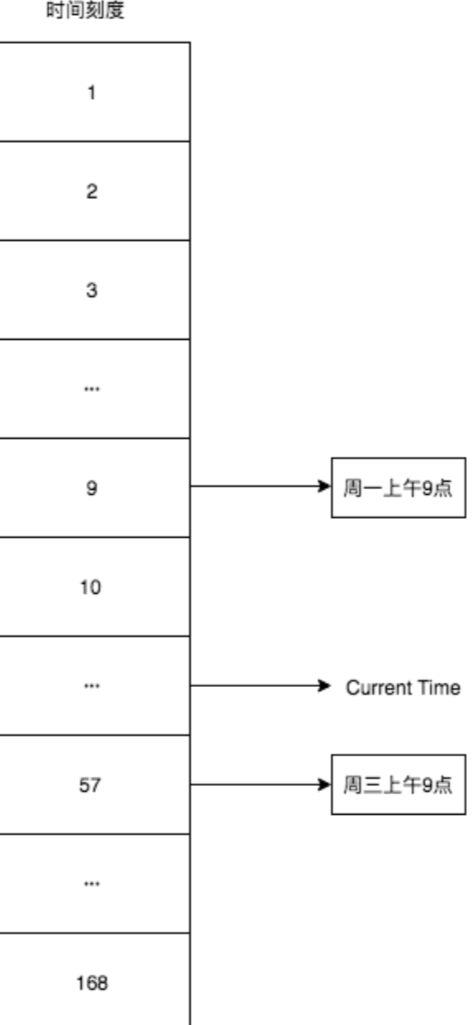
仔细思考一下,会发现这中方式存在几个缺陷:
- 时间刻度太多会导致时间轮走到的多数刻度没有任务执行,比如一个月就2个任务,我得移动720次,其中718次是无用功。
- 时间刻度太多会导致存储空间变大,利用率变低,比如一个月就2个任务,我得需要大小是720的数组,如果我的执行时间的粒度精确到秒,那就更恐怖了。
于是乎,聪明的你脑袋一转,想到另一个办法:
round 的时间轮算法
这次我不增加时间轮的刻度了,刻度还是24个,现在有三个任务需要执行,
- 任务一每周二上午九点。
- 任务二每周四上午九点。
- 任务三每个月12号上午九点。
比如现在是9月11号星期二上午10点,时间轮转一圈是24小时,
任务一下次执行(下周二上午九点),需要时间轮转过6圈后,到第7圈的第9个刻度开始执行。
任务二下次执行第3圈的第9个刻度,任务三是第2圈的第9个刻度。
为了处理上面提到的问题,我们可以在每个定时任务中增设一个 round 字段,用以标识当前任务还需要在时间轮中遍历几轮,才进入执行的时间判断轮。其执行逻辑为:每次遍历到一个时间格后,其任务队列上的所有任务 round 字段减 1,如果 round 字段变为 0,则将任务移出队列,提交给异步线程池来执行其内容。如果这是一个重复任务,那么提交后再将它重新添加到任务队列中。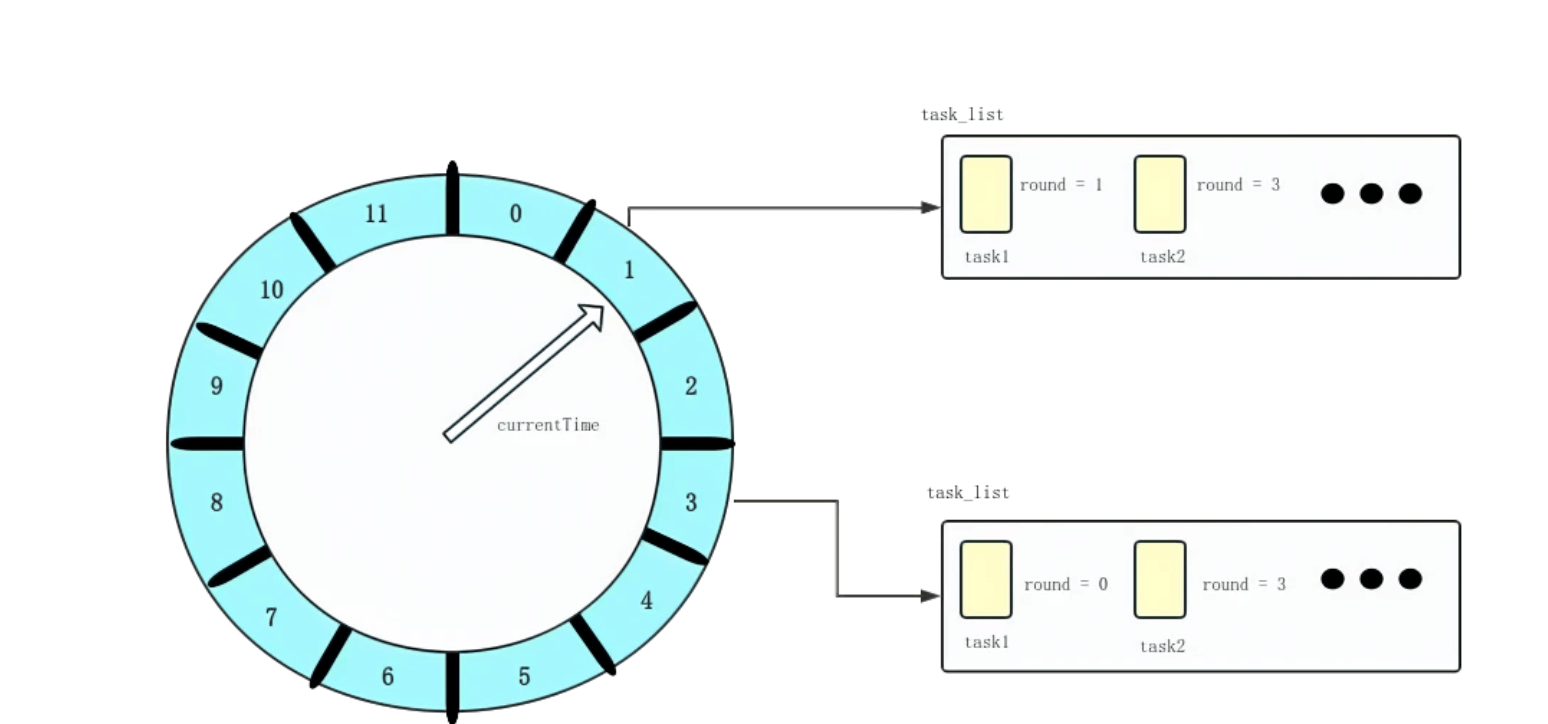
假设现在将时间轮的精度设置为秒,时间轮共有 60 个时间格,那么一个 130 秒后执行的任务,可以将其 round 字段设为 2,并将任务加入到时间刻度为 10 的任务队列中。即对于间隔时间为 x 的定时任务:
- round = x / 60 (整除)
- 刻度位置 pos = x % 60
这种方式虽然减少了时间轮的刻度个数,但并没有减少轮询线程的轮询次数,其效率还是相对比较低。时间轮每遍历一个时间刻度,就要完成一次判断和执行的操作,其运行效率与一般的任务队列差别不大,并没有太大的效率提升。完成了一次遍历,但是并没有提交可执行的任务,这种现象可以称之为“空轮询”。
这样做能解决时间轮刻度范围过大造成的空间浪费,但是却带来了另一个问题:时间轮每次都需要遍历任务列表,耗时增加,当时间轮刻度粒度很小(秒级甚至毫秒级),任务列表又特别长时,这种遍历的办法是不可接受的。
分层时间轮算法
另一种对简单时间轮算法改良的方案,可以参照钟表中时、分、秒的设计,设置三个级别的时间轮,分别代表时、分、秒,且每个轮分别带有 24、60、60 个刻度。这样子三个时间轮结合使用,就能表达一天内所有的时间刻度了。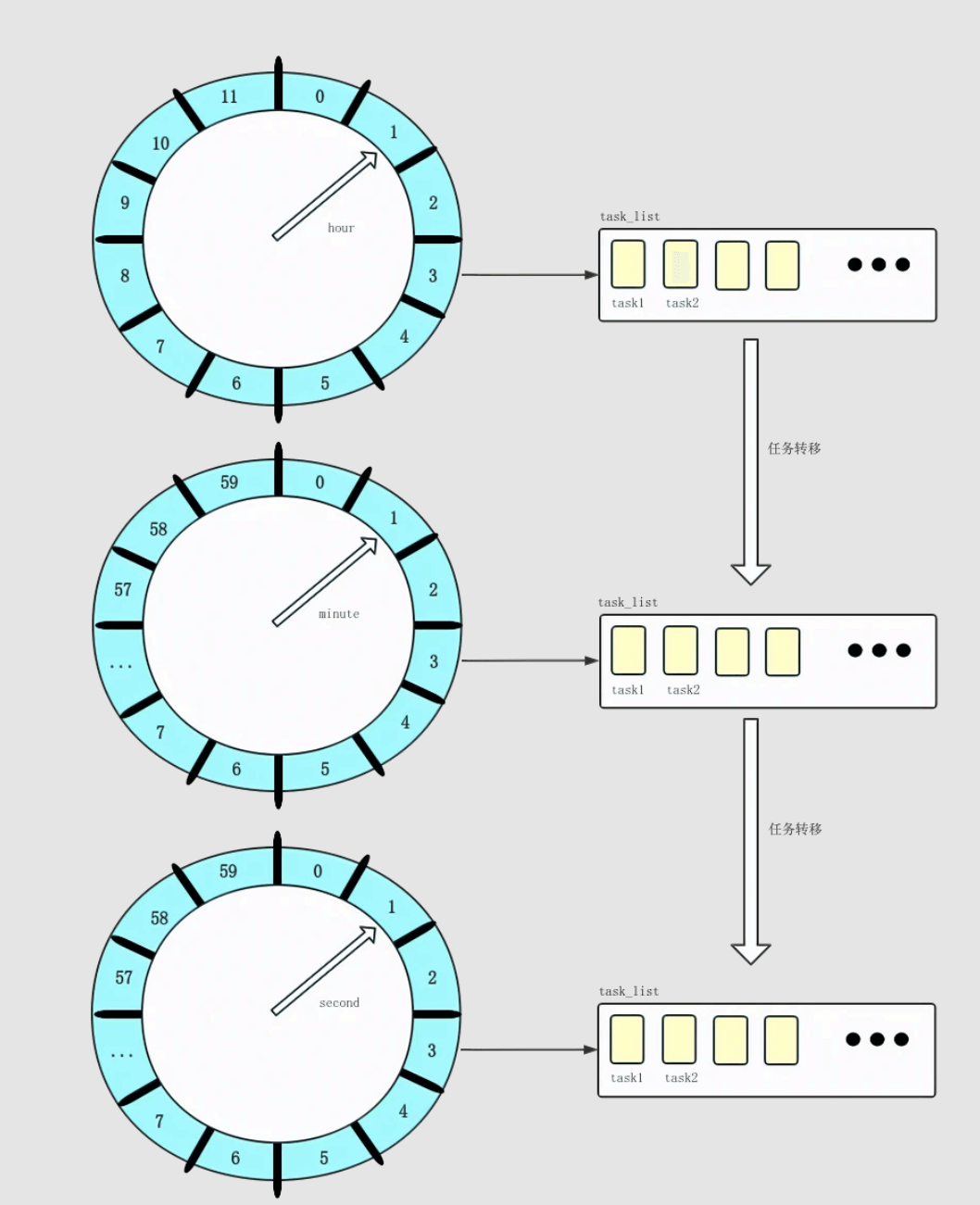
当 hour 时间轮的轮询线程轮询到执行的时间格时,其对应的任务队列已达到其执行的 hour 时间。此时这些任务需转移到下一层 minute 时间轮中,根据其执行时间的 minute 位,插入到对应的任务队列中。后续的步骤都类似,直至到最后一层 second 的时间轮中,被轮询到的队列即可提交其所有的任务到异步执行线程池中。
采用分层时间轮的方式,不需要引入 round 字段,只要在最后一级遍历到的任务队列,必然是可提交执行的,进而避免了空轮询的问题,提高了轮询的效率。每个时间轮的遍历由不同的轮询线程实现,虽然引入的线程并发,但是线程数仅仅跟时间轮的级数有关,并不会随着任务数量的增加的增加。
分层时间轮是这样一种思想:
- 针对时间复杂度的问题:不做遍历计算round,凡是任务列表中的都应该是应该被执行的,直接全部取出来执行。
- 针对空间复杂度的问题:分层,每个时间粒度对应一个时间轮,多个时间轮之间进行级联协作。
第一点很好理解,第二点有必要举个例子来说明:
比如我有三个任务:
- 任务一每周二上午九点。
- 任务二每周四上午九点。
- 任务三每个月12号上午九点。
三个任务涉及到四个时间单位:小时、天、星期、月份。
拿任务三来说,任务三得到执行的前提是,时间刻度先得来到12号这一天,然后才需要关注其更细一级的时间单位:上午9点。
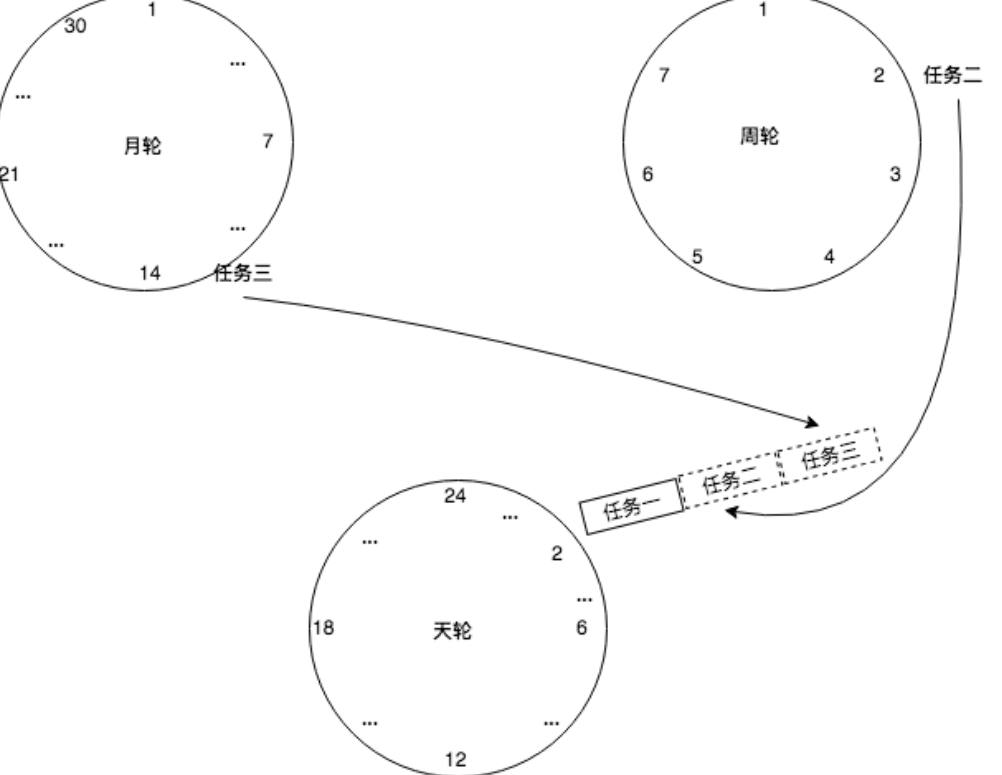
基于这个思想,我们可以设置三个时间轮:月轮、周轮、天轮。
- 月轮的时间刻度是天。
- 周轮的时间刻度是天。
- 天轮的时间刻度是小时。
初始添加任务时,任务一添加到天轮上,任务二添加到周轮上,任务三添加到月轮上。
三个时间轮以各自的时间刻度不停流转。
当周轮移动到刻度2(星期二)时,取出这个刻度下的任务,丢到天轮上,天轮接管该任务,到9点执行。
同理,当月轮移动到刻度12(12号)时,取出这个刻度下的任务,丢到天轮上,天轮接管该任务,到9点执行。
这样就可以做到既不浪费空间,有不浪费时间。
时间轮算法的进一步优化
通过分层时间轮,我们可以将一系列定时任务根据其执行时间进行分组和排序,依次分配到时间轮的对应时间格中。只要时间轮的指针到达特定时间格,相应任务队列中的所有任务即可提交执行。但是在实际应用中,真正需要执行任务的时间格在所有时间格中的占比是很小的。假如第一个待执行的任务列表的 expiration 为 100s,以每秒推进一格的方案来看,在获取到第一个可执行的任务列表前,会出现 99 次的空轮询,也就是时间轮指针推进了,但并没有任务执行的情况。这种空轮询的存在,并没有太大的业务含义,白白耗费了系统的性能资源。
为了处理好空轮询的问题,这里可以再引入 DelayQueue 来维护每个定时任务列表,进而减少空轮询的次数,实现精确轮询。具体方案就是,根据 DelayQueue 中前后相邻的任务队列的 expiration 来确定时间轮指针推进的时间,精确地在下一个任务执行的时间点时对该列表进行轮询。
性能分析
一个初级的定时任务框架,可以采用有序任务队列 + 轮询线程的方式进行实现,有序任务队列通常基于优先队列(堆)进行实现,因此其任务的插入和删除的时间复杂度为 O(log N) 。而时间轮算法,能够将时间复杂度降低至 O(1),效率明显得到提升。而算法的主要性能损耗,则体现在多个时间轮轮询线程的时间推进,以及他们与任务执行线程之间的切换。这方面的复杂度,明显小于基本的时间轮算法还有普通的任务队列。
定义:
- n - 任务数量
- k - 多线程轮询的线程数
- 常数 M - 全时段时间轮刻度数量(空间单位数)
- 常数 L - 单 round 时间轮刻度数量(空间单位数)
- li - 第 i 层时间轮刻度数量(空间单位数)
- T - 存在任务队列的空间单位数
多级时间轮算法的简单实现
1 | package timeWheel; |
参考链接:https://blog.csdn.net/sinat_36645384/article/details/127463600
参考链接:https://blog.csdn.net/yu757371316/article/details/107320068
原文链接:https://blog.csdn.net/grandachn/article/details/130137300
三、跳表
一、跳表的定义
- 跳表,又叫做跳跃表、跳跃列表,在有序链表的基础上增加了“跳跃”的功能
- 跳表在原来的有序链表上加上了多级索引,通过索引来快速查找;可以支持快速的删除、插入和查找操作。
- 跳表实际上是一种增加了前向指针的链表,是一种随机化的数据结构
Redis中的SortedSet、LevelDB中的MemTable都用到了跳表- 对比平衡树, 跳表的实现和维护会更加简单, 跳表的搜索、删除、添加的平均时间复杂度是 O(logn)
它允许快速查询,插入和删除一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是O(logn)。快速查询是通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集(见右边的示意图)。一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止。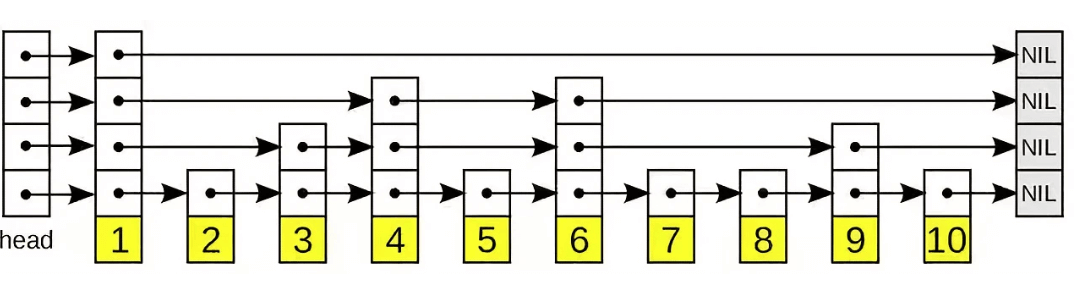
二、跳表的数据结构图型
使用跳表优化链表
跳表的演化过程
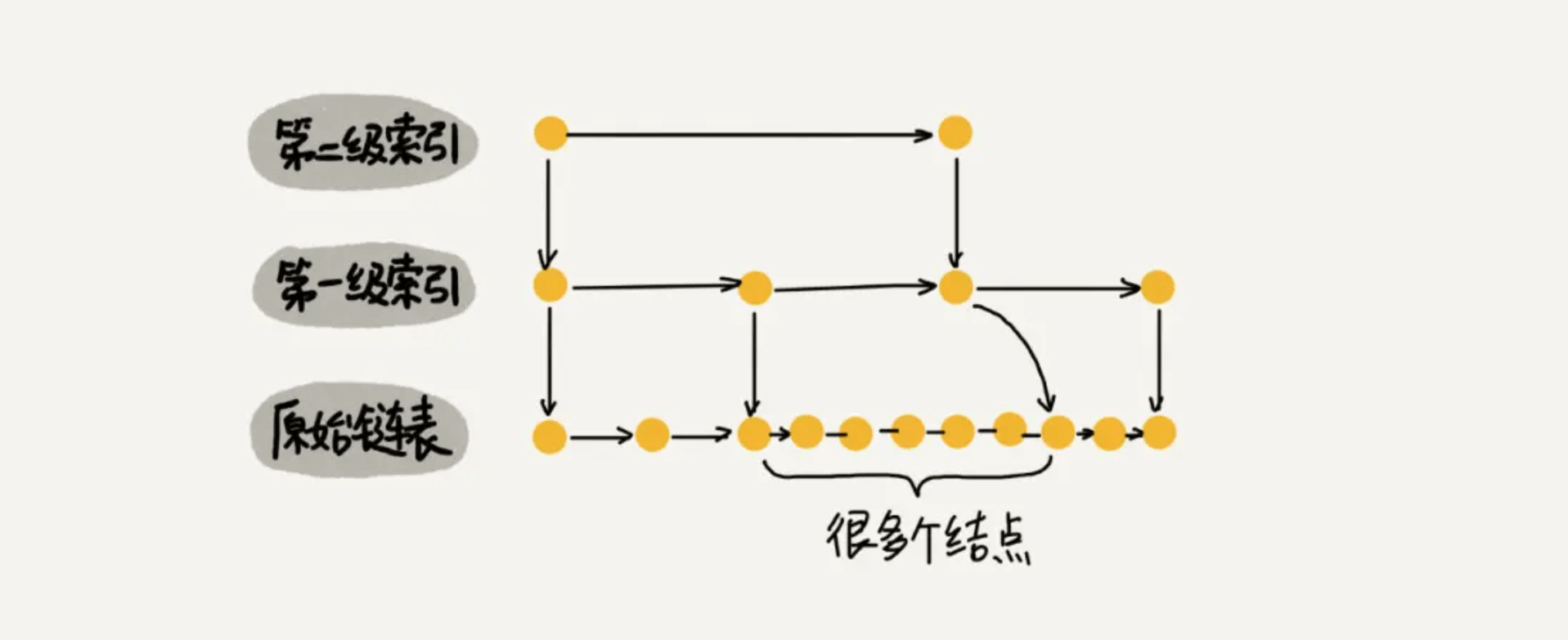
对于单链表来说,即使数据是已经排好序的,想要查询其中的一个数据,只能从头开始遍历链表,这样效率很低,时间复杂度很高,是 O(n)。 那我们有没有什么办法来提高查询的效率呢?我们可以为链表建立一个“索引”,这样查找起来就会更快,如下图所示,我们在原始链表的基础上,每两个结点提取一个结点建立索引,我们把抽取出来的结点叫作索引层或者索引,down 表示指向原始链表节点的指针。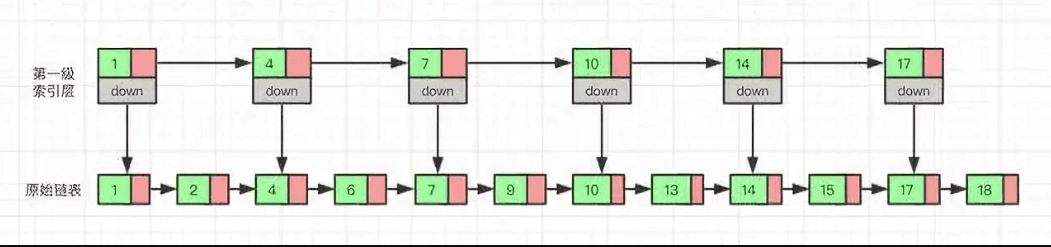
从单链表开始说起
下图是一个简单的有序单链表,单链表的特性就是每个元素存放下一个元素的引用。即:通过第一个元素可以找到第二个元素,通过第二个元素可以找到第三个元素,依次类推,直到找到最后一个元素。
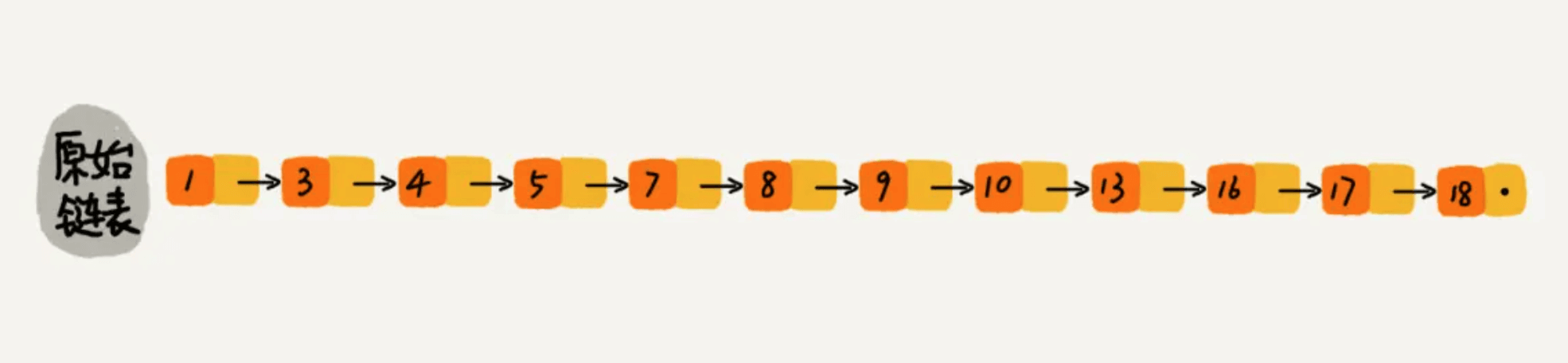 现在我们有个场景,想快速找到上图链表中的 10 这个元素,只能从头开始遍历链表,直到找到我们需要找的元素。查找路径:1、3、4、5、7、8、9、10。这样的查找效率很低,平均时间复杂度很高O(n)。那有没有办法提高链表的查找速度呢?如下图所示,我们从链表中每两个元素抽出来,加一级索引,一级索引指向了原始链表,即:通过一级索引 7 的down指针可以找到原始链表的 7 。那现在怎么查找 10 这个元素呢?
现在我们有个场景,想快速找到上图链表中的 10 这个元素,只能从头开始遍历链表,直到找到我们需要找的元素。查找路径:1、3、4、5、7、8、9、10。这样的查找效率很低,平均时间复杂度很高O(n)。那有没有办法提高链表的查找速度呢?如下图所示,我们从链表中每两个元素抽出来,加一级索引,一级索引指向了原始链表,即:通过一级索引 7 的down指针可以找到原始链表的 7 。那现在怎么查找 10 这个元素呢?
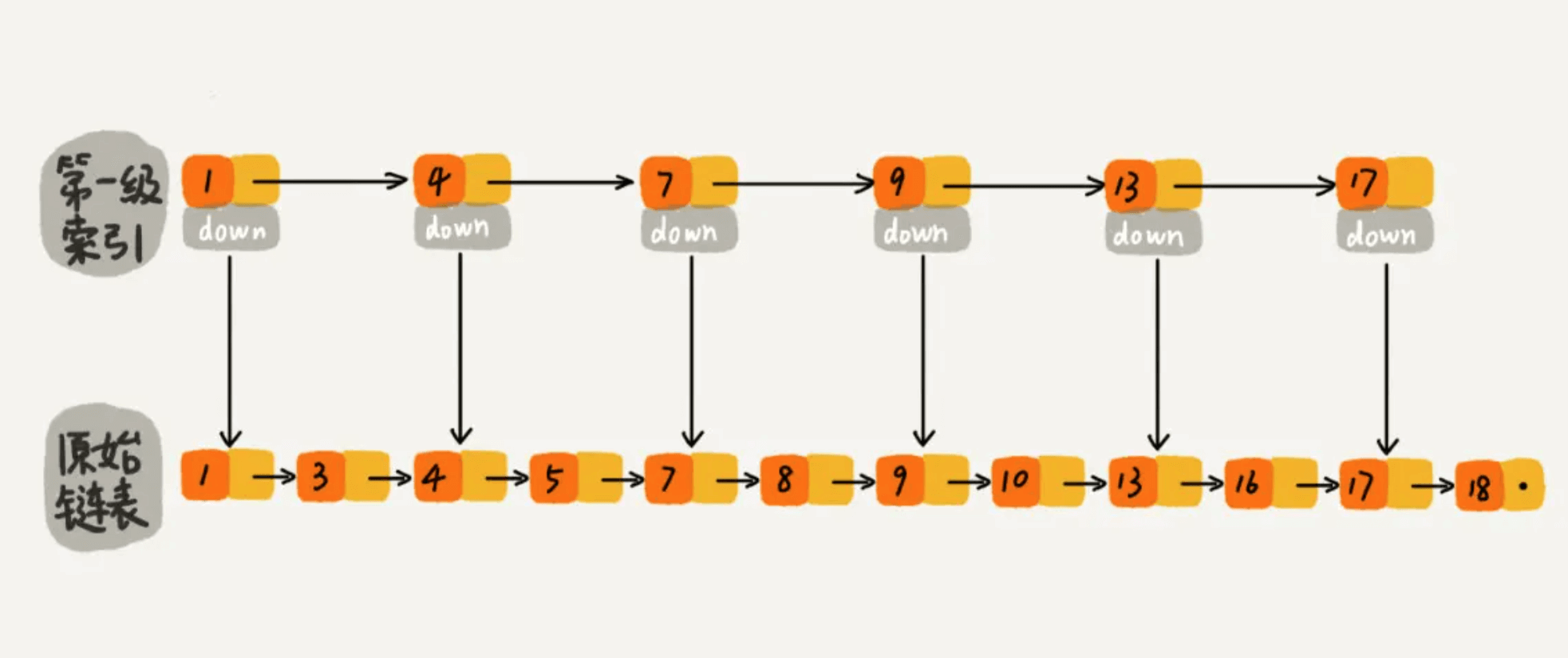
先在索引找 1、4、7、9,遍历到一级索引的 9 时,发现 9 的后继节点是 13,比 10 大,于是不往后找了,而是通过 9 找到原始链表的 9,然后再往后遍历找到了我们要找的 10,遍历结束。有没有发现,加了一级索引后,查找路径:1、4、7、9、10,查找节点需要遍历的元素相对少了,我们不需要对 10 之前的所有数据都遍历,查找的效率提升了。
那如果加二级索引呢?如下图所示,查找路径:1、7、9、10。是不是找 10 的效率更高了?这就是跳表的思想,用“空间换时间”,通过给链表建立索引,提高了查找的效率。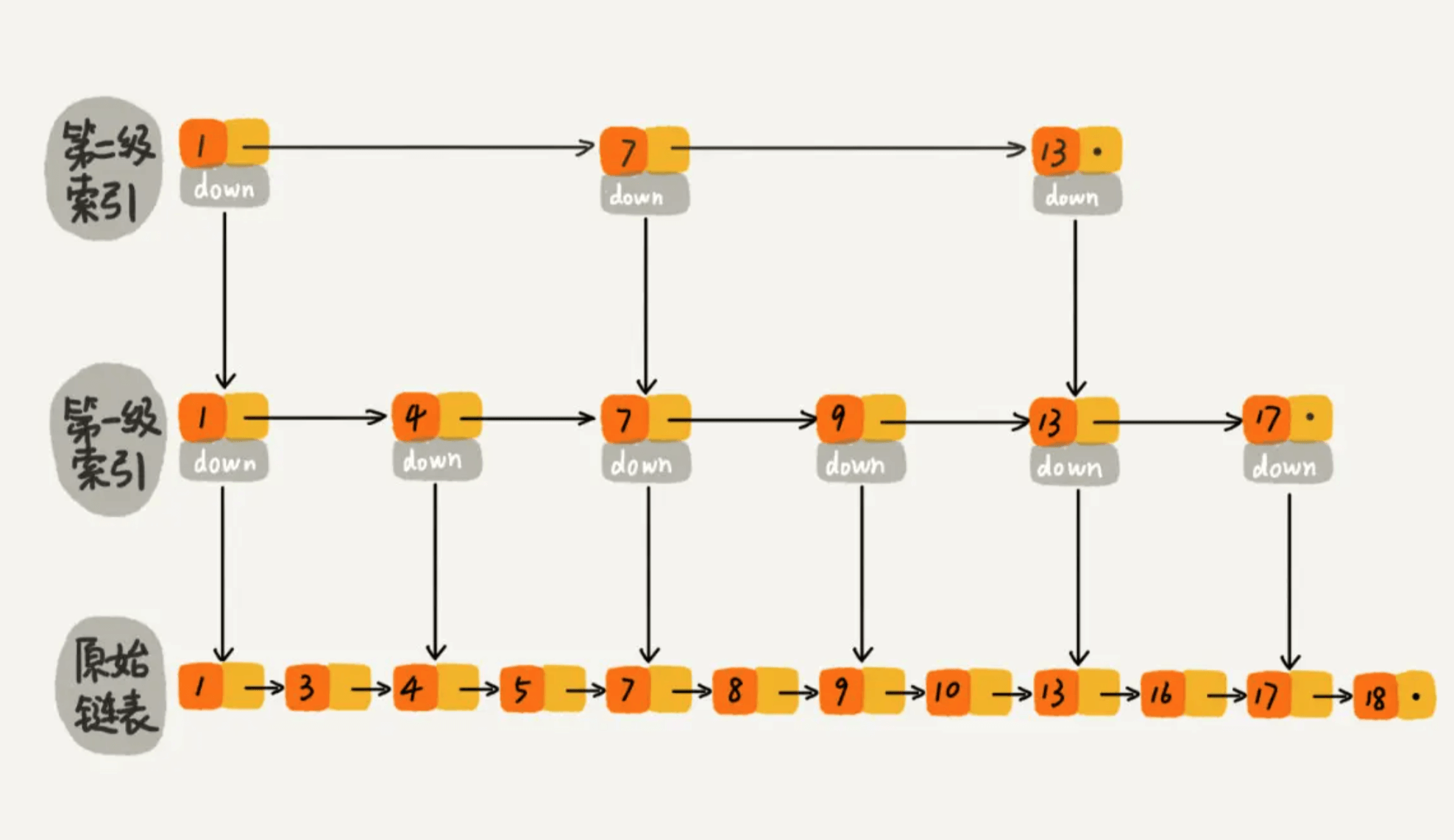
可能同学们会想,从上面案例来看,提升的效率并不明显,本来需要遍历8个元素,优化了半天,还需要遍历 4 个元素,其实是因为我们的数据量太少了,当数据量足够大时,效率提升会很大。如下图所示,假如有序单链表现在有1万个元素,分别是 0~9999。现在我们建了很多级索引,最高级的索引,就两个元素 0、5000,次高级索引四个元素 0、2500、5000、7500,依次类推,当我们查找 7890 这个元素时,查找路径为 0、5000、7500 … 7890,通过最高级索引直接跳过了5000个元素,次高层索引直接跳过了2500个元素,从而使得链表能够实现二分查找。由此可以看出,当元素数量较多时,索引提高的效率比较大,近似于二分查找。
![[跳表-6.png]]
到这里大家应该已经明白了什么是跳表。跳表是可以实现二分查找的有序链表。
查找的时间复杂度
既然跳表可以提升链表查找元素的效率,那查找一个元素的时间复杂度到底是多少呢?查找元素的过程是从最高级索引开始,一层一层遍历最后下沉到原始链表。所以,时间复杂度 = 索引的高度 * 每层索引遍历元素的个数。
先来求跳表的索引高度。如下图所示,假设每两个结点会抽出一个结点作为上一级索引的结点,原始的链表有n个元素,则一级索引有n/2 个元素、二级索引有 n/4 个元素、k级索引就有 n/2k个元素。最高级索引一般有2个元素,即:最高级索引 h 满足 2 = n/2h,即 h = log2n - 1,最高级索引 h 为索引层的高度加上原始数据一层,跳表的总高度 h = log2n。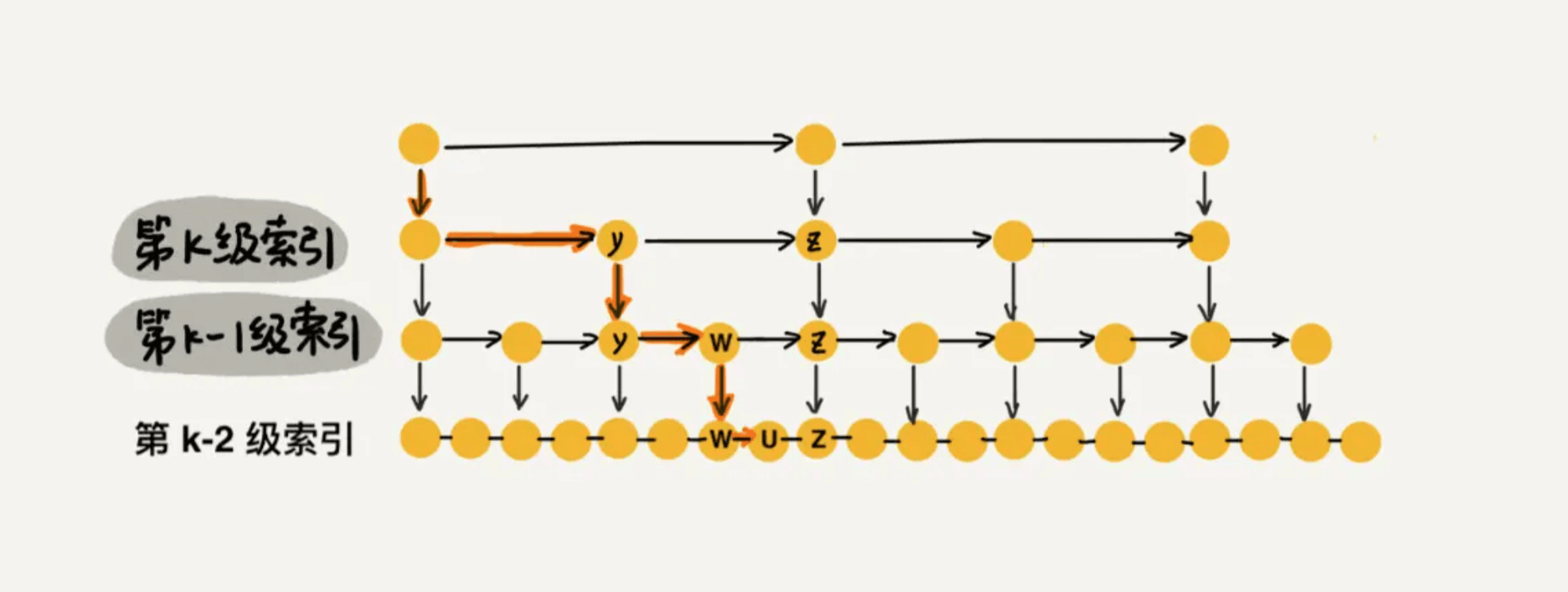
![[查找的时间复杂度证明.png]]
我们看上图中加粗的箭头,表示查找元素 x 的路径,那查找过程中每一层索引最多遍历几个元素呢?
图中所示,现在到达第 k 级索引,我们发现要查找的元素 x 比 y 大比 z 小,所以,我们需要从 y 处下降到 k-1 级索引继续查找,k-1级索引中比 y 大比 z 小的只有一个 w,所以在 k-1 级索引中,我们遍历的元素最多就是 y、w、z,发现 x 比 w大比 z 小之后,再下降到 k-2 级索引。所以,k-2 级索引最多遍历的元素为 w、u、z。其实每级索引都是类似的道理,每级索引中都是两个结点抽出一个结点作为上一级索引的结点。 现在我们得出结论:当每级索引都是两个结点抽出一个结点作为上一级索引的结点时,每一层最多遍历3个结点。
跳表的索引高度 h = log2n,且每层索引最多遍历 3 个元素。所以跳表中查找一个元素的时间复杂度为 O(3*logn),省略常数即:O(logn)。
空间复杂度
跳表通过建立索引,来提高查找元素的效率,就是典型的“空间换时间”的思想,所以在空间上做了一些牺牲,那空间复杂度到底是多少呢?
假如原始链表包含 n 个元素,则一级索引元素个数为 n/2、二级索引元素个数为 n/4、三级索引元素个数为 n/8 以此类推。所以,索引节点的总和是:n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2,**空间复杂度是 O(n)**。
如下图所示:如果每三个结点抽一个结点做为索引,索引总和数就是 n/3 + n/9 + n/27 + … + 9 + 3 + 1= n/2,减少了一半。所以我们可以通过较少索引数来减少空间复杂度,但是相应的肯定会造成查找效率有一定下降,我们可以根据我们的应用场景来控制这个阈值,看我们更注重时间还是空间。
But,索引结点往往只需要存储 key 和几个指针,并不需要存储完整的对象,所以当对象比索引结点大很多时,索引占用的额外空间就可以忽略了。举个例子:我们现在需要用跳表来给所有学生建索引,学生有很多属性:学号、姓名、性别、身份证号、年龄、家庭住址、身高、体重等。学生的各种属性只需要在原始链表中存储一份即可,我们只需要用学生的学号(int 类型的数据)建立索引,所以索引相对原始数据而言,占用的空间可以忽略。
三、跳表插入数据
插入数据看起来也很简单,跳表的原始链表需要保持有序,所以我们会向查找元素一样,找到元素应该插入的位置。如下图所示,要插入数据6,整个过程类似于查找6,整个的查找路径为 1、1、1、4、4、5。查找到第底层原始链表的元素 5 时,发现 5 小于 6 但是后继节点 7 大于 6,所以应该把 6 插入到 5 之后 7 之前。整个时间复杂度为查找元素的时间复杂度 O(logn)。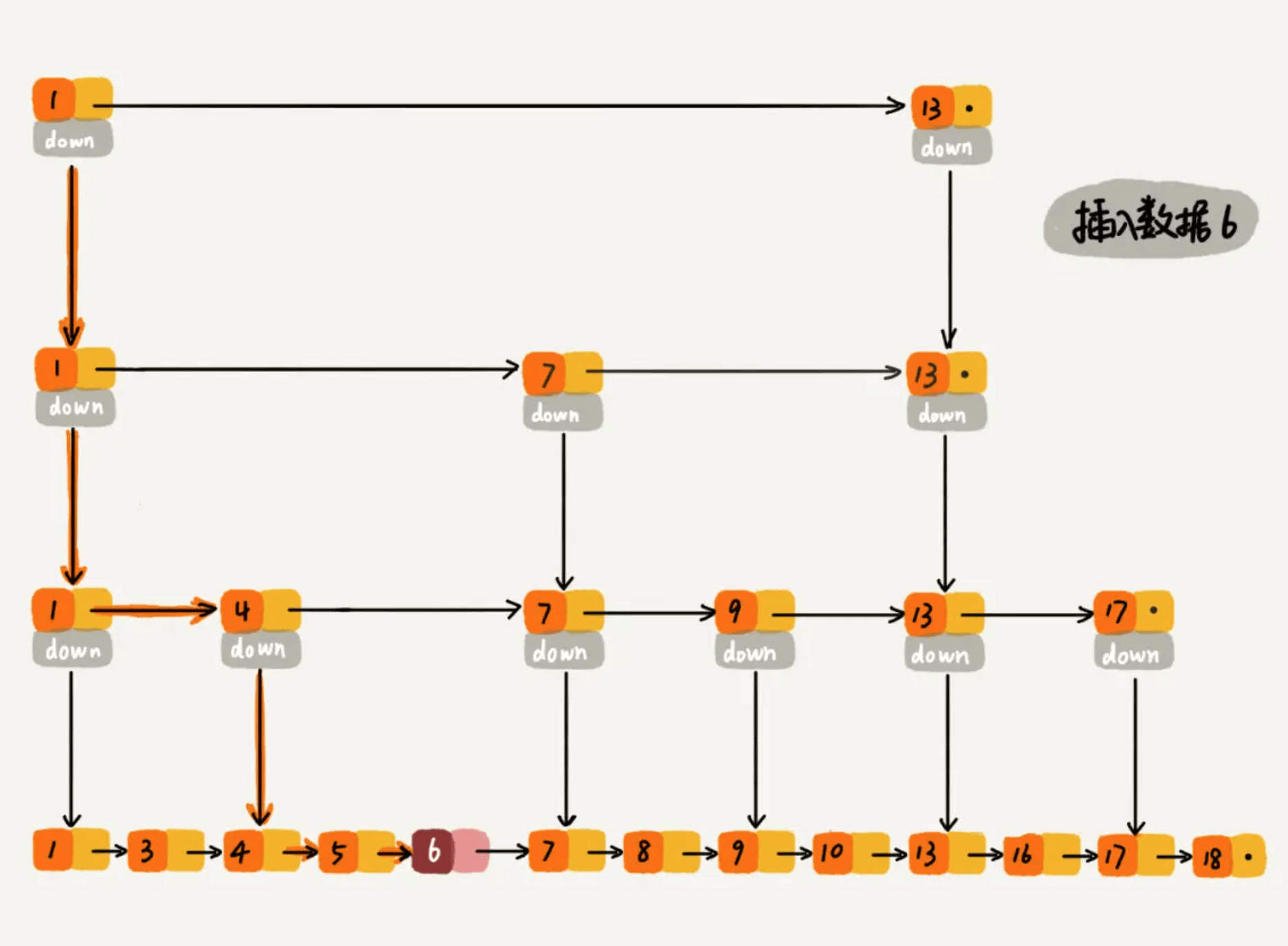
如下图所示,假如一直往原始列表中添加数据,但是不更新索引,就可能出现两个索引节点之间数据非常多的情况,极端情况,跳表退化为单链表,从而使得查找效率从 O(logn) 退化为 O(n)。那这种问题该怎么解决呢?我们需要在插入数据的时候,索引节点也需要相应的增加、或者重建索引,来避免查找效率的退化。那我们该如何去维护这个索引呢?
比较容易理解的做法就是完全重建索引,我们每次插入数据后,都把这个跳表的索引删掉全部重建,重建索引的时间复杂度是多少呢?因为索引的空间复杂度是 O(n),即:索引节点的个数是 O(n) 级别,每次完全重新建一个 O(n) 级别的索引,时间复杂度也是 O(n) 。造成的后果是:为了维护索引,导致每次插入数据的时间复杂度变成了 O(n)。
那有没有其他效率比较高的方式来维护索引呢?假如跳表每一层的晋升概率是 1/2,最理想的索引就是在原始链表中每隔一个元素抽取一个元素做为一级索引。换种说法,我们在原始链表中随机的选 n/2 个元素做为一级索引是不是也能通过索引提高查找的效率呢? 当然可以了,因为一般随机选的元素相对来说都是比较均匀的。如下图所示,随机选择了n/2 个元素做为一级索引,虽然不是每隔一个元素抽取一个,但是对于查找效率来讲,影响不大,比如我们想找元素 16,仍然可以通过一级索引,使得遍历路径较少了将近一半。如果抽取的一级索引的元素恰好是前一半的元素 1、3、4、5、7、8,那么查找效率确实没有提升,但是这样的概率太小了。我们可以认为:当原始链表中元素数量足够大,且抽取足够随机的话,我们得到的索引是均匀的。我们要清楚设计良好的数据结构都是为了应对大数据量的场景,如果原始链表只有 5 个元素,那么依次遍历 5 个元素也没有关系,因为数据量太少了。所以,我们可以维护一个这样的索引:随机选 n/2 个元素做为一级索引、随机选 n/4 个元素做为二级索引、随机选 n/8 个元素做为三级索引,依次类推,一直到最顶层索引。这里每层索引的元素个数已经确定,且每层索引元素选取的足够随机,所以可以通过索引来提升跳表的查找效率。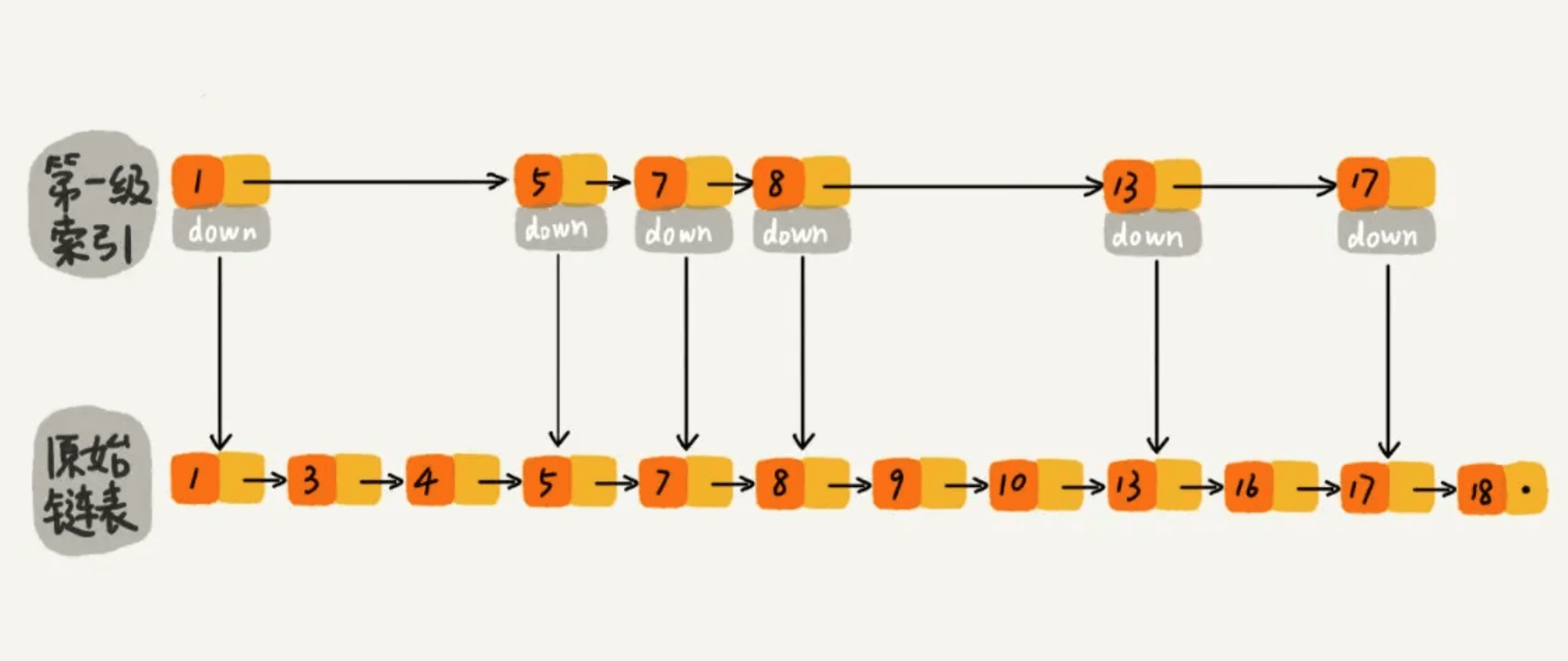
那代码该如何实现,才能使跳表满足上述这个样子呢?可以在每次新插入元素的时候,尽量让该元素有 1/2 的几率建立一级索引、1/4 的几率建立二级索引、1/8 的几率建立三级索引,以此类推,就能满足我们上面的条件。现在我们就需要一个概率算法帮我们把控这个 1/2、1/4、1/8 … ,当每次有数据要插入时,先通过概率算法告诉我们这个元素需要插入到几级索引中,然后开始维护索引并把数据插入到原始链表中。下面开始讲解这个概率算法代码如何实现。
我们可以实现一个 randomLevel() 方法,该方法会随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数),且该方法有 1/2 的概率返回 1、1/4 的概率返回 2、1/8的概率返回 3,以此类推。
- randomLevel() 方法返回 1 表示当前插入的该元素不需要建索引,只需要存储数据到原始链表即可(概率 1/2)
- randomLevel() 方法返回 2 表示当前插入的该元素需要建一级索引(概率 1/4)
- randomLevel() 方法返回 3 表示当前插入的该元素需要建二级索引(概率 1/8)
- randomLevel() 方法返回 4 表示当前插入的该元素需要建三级索引(概率 1/16)
- 。。。以此类推
所以,通过 randomLevel() 方法,我们可以控制整个跳表各级索引中元素的个数。重点来了:randomLevel() 方法返回 2 的时候会建立一级索引,我们想要一级索引中元素个数占原始数据的 1/2,但是 randomLevel() 方法返回 2 的概率为 1/4,那是不是有矛盾呢?明明说好的 1/2,结果一级索引元素个数怎么变成了原始链表的 1/4?我们先看下图,应该就明白了。
假设我们在插入元素 6 的时候,randomLevel() 方法返回 1,则我们不会为 6 建立索引。插入 7 的时候,randomLevel() 方法返回3 ,所以我们需要为元素 7 建立二级索引。这里我们发现了一个特点:当建立二级索引的时候,同时也会建立一级索引;当建立三级索引时,同时也会建立一级、二级索引。所以,一级索引中元素的个数等于 [ 原始链表元素个数 ] * _[ randomLevel() 方法返回值 > 1 的概率 ]_。因为 randomLevel() 方法返回值 > 1就会建索引,凡是建索引,无论几级索引必然有一级索引,所以一级索引中元素个数占原始数据个数的比率为 randomLevel() 方法返回值 > 1 的概率。那 randomLevel() 方法返回值 > 1 的概率是多少呢?因为 randomLevel() 方法随机生成 1~MAX_LEVEL 的数字,且 randomLevel() 方法返回值 1 的概率为 1/2,则 randomLevel() 方法返回值 > 1 的概率为 1 - 1/2 = 1/2。即通过上述流程实现了一级索引中元素个数占原始数据个数的 1/2。
同理,当 randomLevel() 方法返回值 > 2 时,会建立二级或二级以上索引,都会在二级索引中增加元素,因此二级索引中元素个数占原始数据的比率为 randomLevel() 方法返回值 > 2 的概率。 randomLevel() 方法返回值 > 2 的概率为 1 减去 randomLevel() = 1 或 =2 的概率,即 1 - 1/2 - 1/4 = 1/4。OK,达到了我们设计的目标:二级索引中元素个数占原始数据的 1/4。
以此类推,可以得出,遵守以下两个条件:
- randomLevel() 方法,随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数),且有 1/2的概率返回 1、1/4的概率返回 2、1/8的概率返回 3 …
- randomLevel() 方法返回 1 不建索引、返回2建一级索引、返回 3 建二级索引、返回 4 建三级索引 …
就可以满足我们想要的结果,即:一级索引中元素个数应该占原始数据的 1/2,二级索引中元素个数占原始数据的 1/4,三级索引中元素个数占原始数据的 1/8 ,依次类推,一直到最顶层索引。
但是问题又来了,怎么设计这么一个 randomLevel() 方法呢?直接撸代码:
1 | // 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 : |
上述代码可以实现我们的功能,而且,我们的案例中晋升概率 SKIPLIST_P 设置的 1/2,即:每两个结点抽出一个结点作为上一级索引的结点。如果我们想节省空间利用率,可以适当的降低代码中的 SKIPLIST_P,从而减少索引元素个数,Redis 的 zset 中 SKIPLIST_P 设定的 0.25。下图所示,是Redis t_zset.c 中 zslRandomLevel 函数的实现:

Redis 源码中 (random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF) 在功能上等价于我代码中的 Math.random() < SKIPLIST_P ,只不过 Redis 作者 antirez 使用位运算来提高浮点数比较的效率。
整体思路大家应该明白了,那插入数据时维护索引的时间复杂度是多少呢?**元素插入到单链表的时间复杂度为 O(1)**,我们索引的高度最多为 logn,当插入一个元素 x 时,最坏的情况就是元素 x 需要插入到每层索引中,所以插入数据到各层索引中,最坏时间复杂度是 O(logn)。
整体插入过程
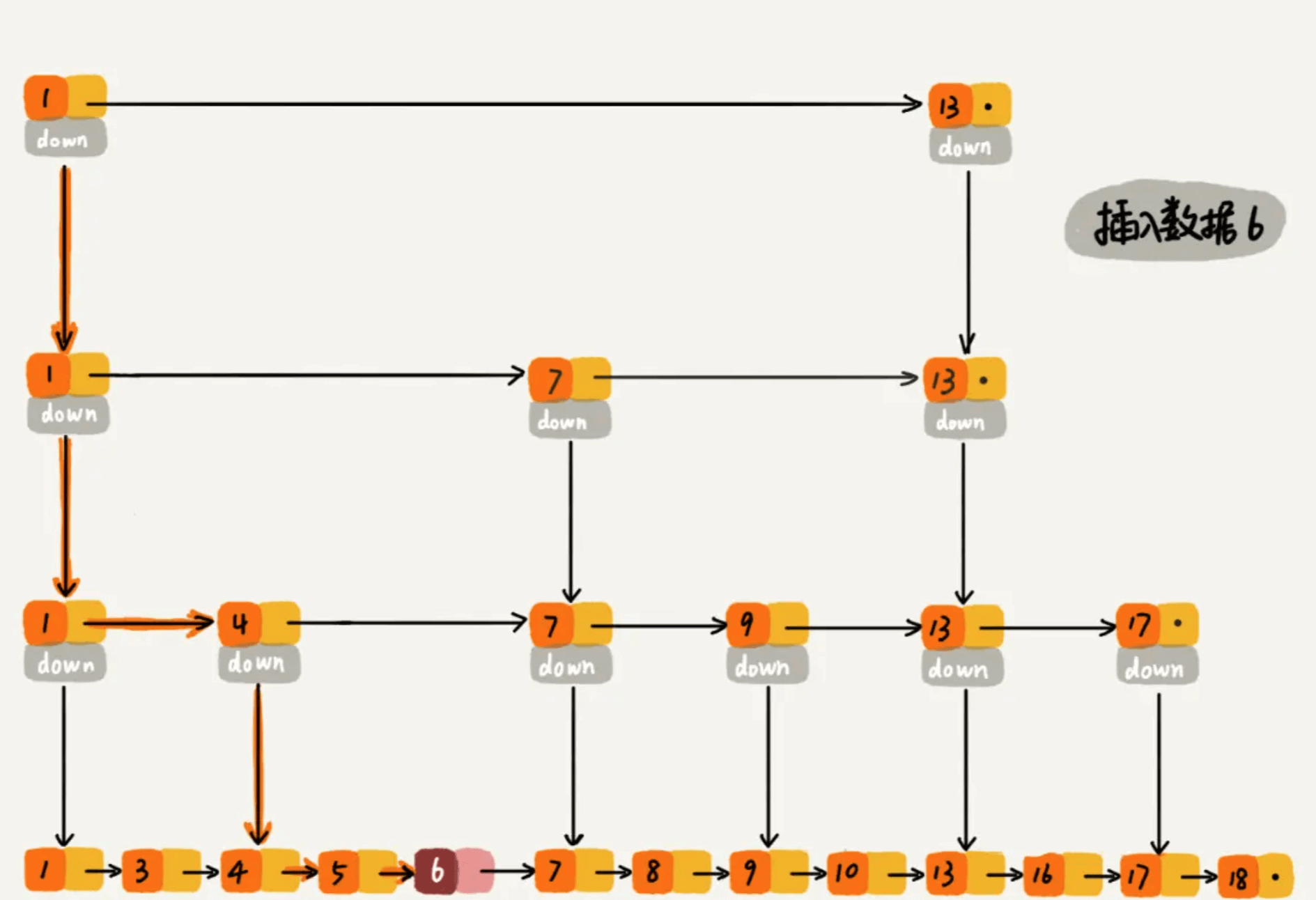
过程大概理解了,再通过一个例子描述一下跳表插入数据的全流程。现在我们要插入数据 6 到跳表中,首先 randomLevel() 返回 3,表示需要建二级索引,即:一级索引和二级索引需要增加元素 6。该跳表目前最高三级索引,首先找到三级索引的 1,发现 6 比 1大比 13小,所以,从 1 下沉到二级索引。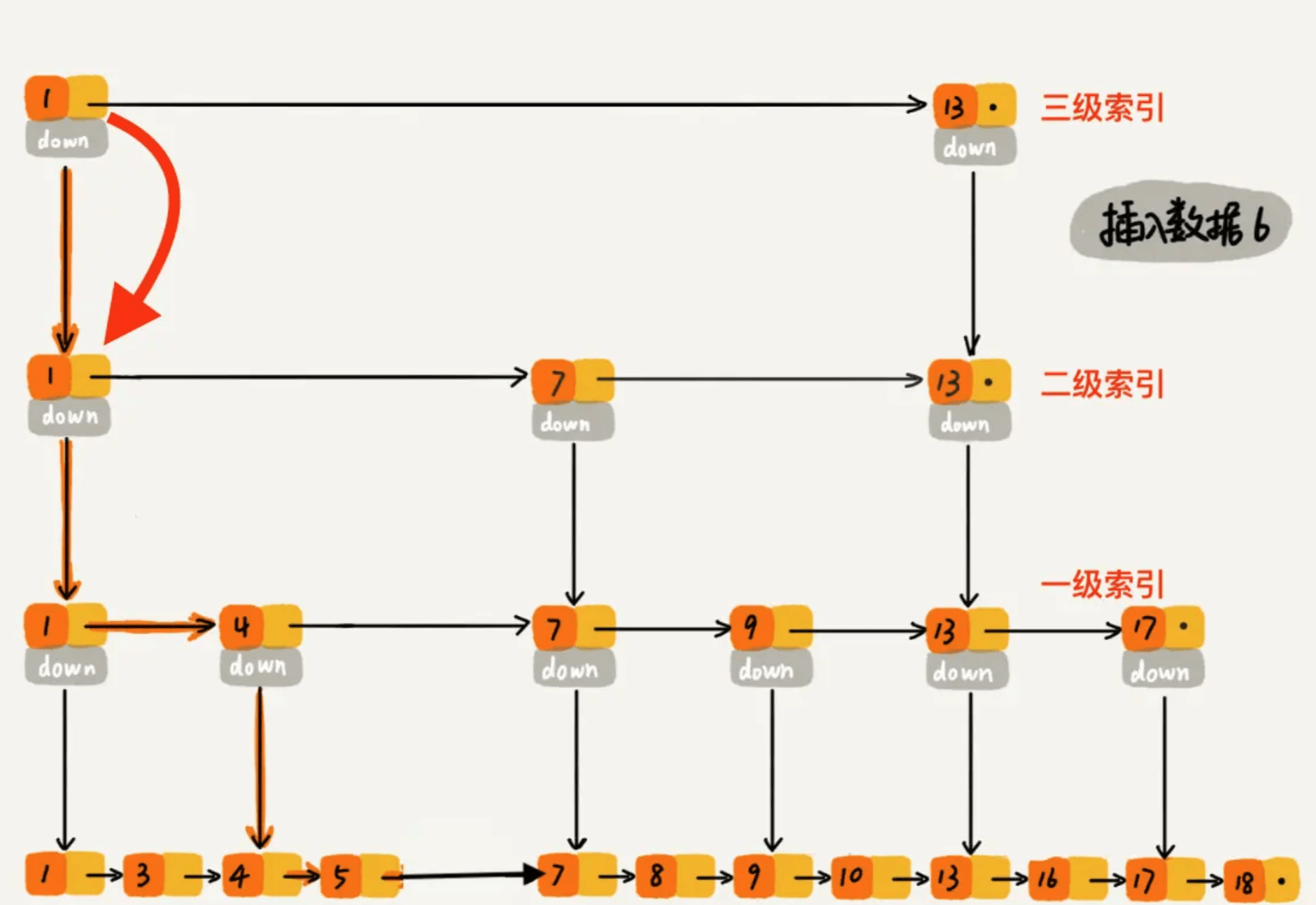
下沉到二级索引后,发现 6 比 1 大比 7 小,此时需要在二级索引中 1 和 7 之间加一个元素6 ,并从元素 1 继续下沉到一级索引。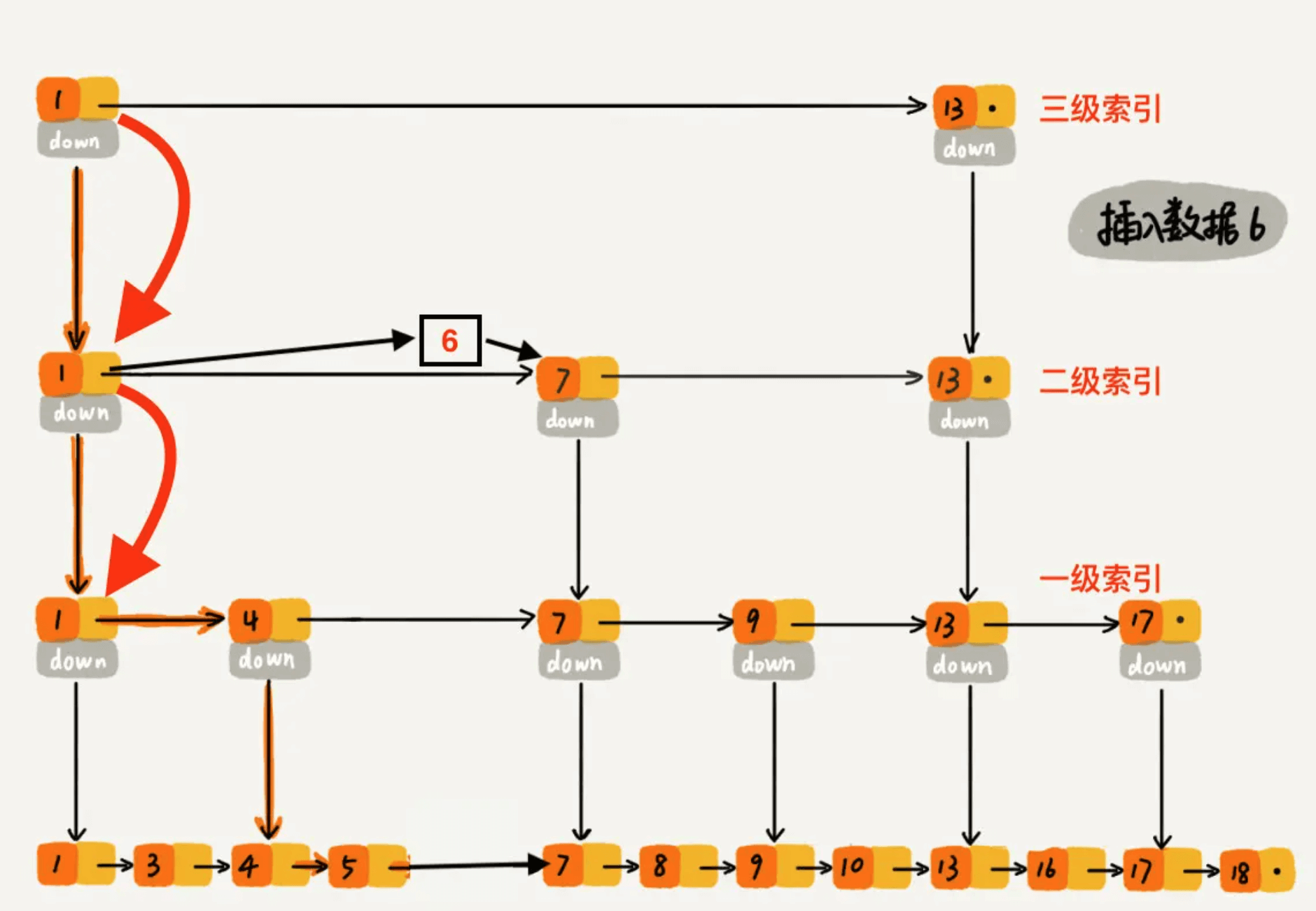
下沉到一级索引后,发现 6 比 1 大比 4 大,所以往后查找,发现 6 比 4 大比 7 小,此时需要在一级索引中 4 和 7 之间加一个元素 6 ,并把二级索引的 6 指向 一级索引的 6,最后,从元素 4 继续下沉到原始链表。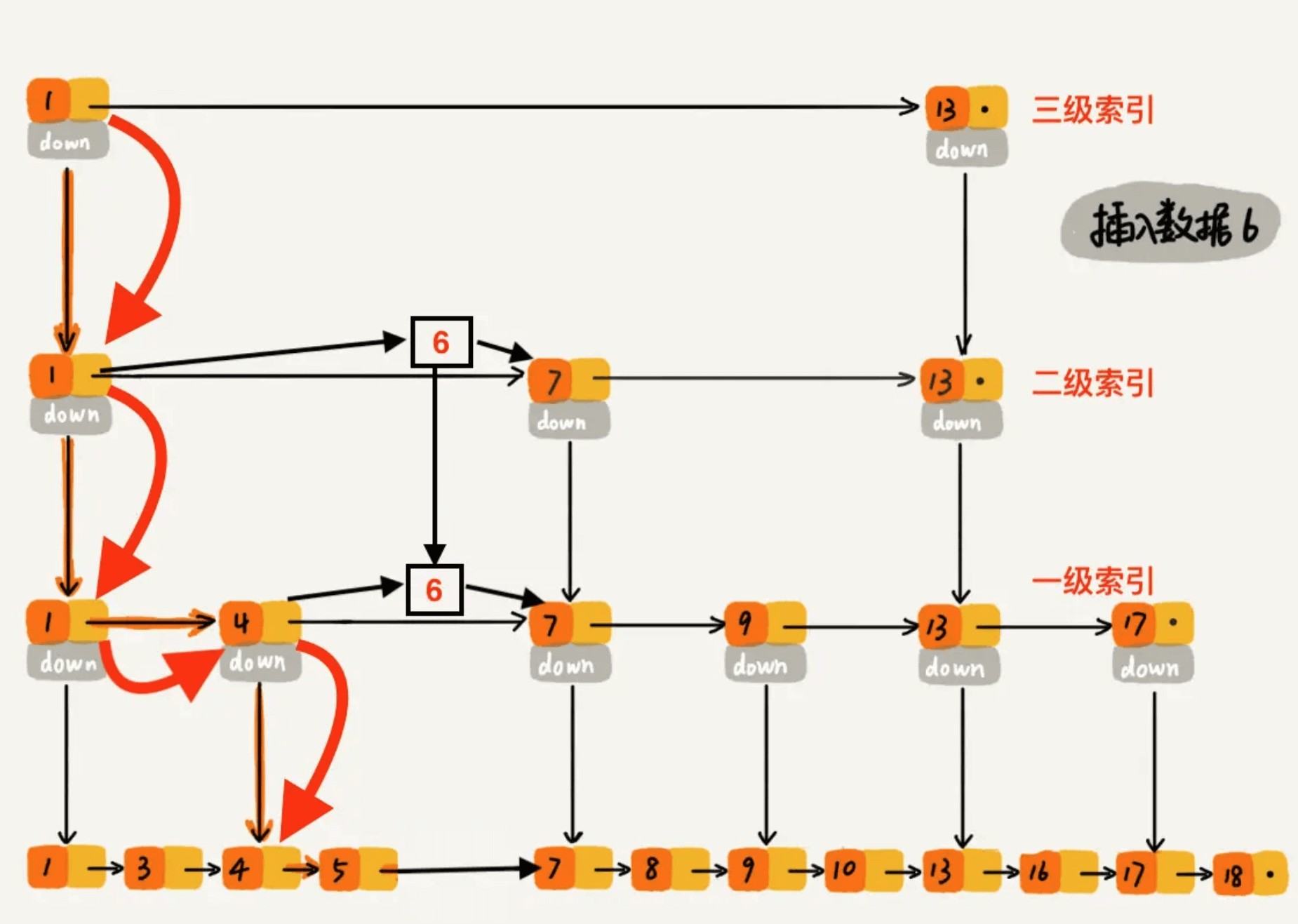
下沉到原始链表后,就比较简单了,发现 4、5 比 6小,7比6大,所以将6插入到 5 和 7 之间即可,整个插入过程结束。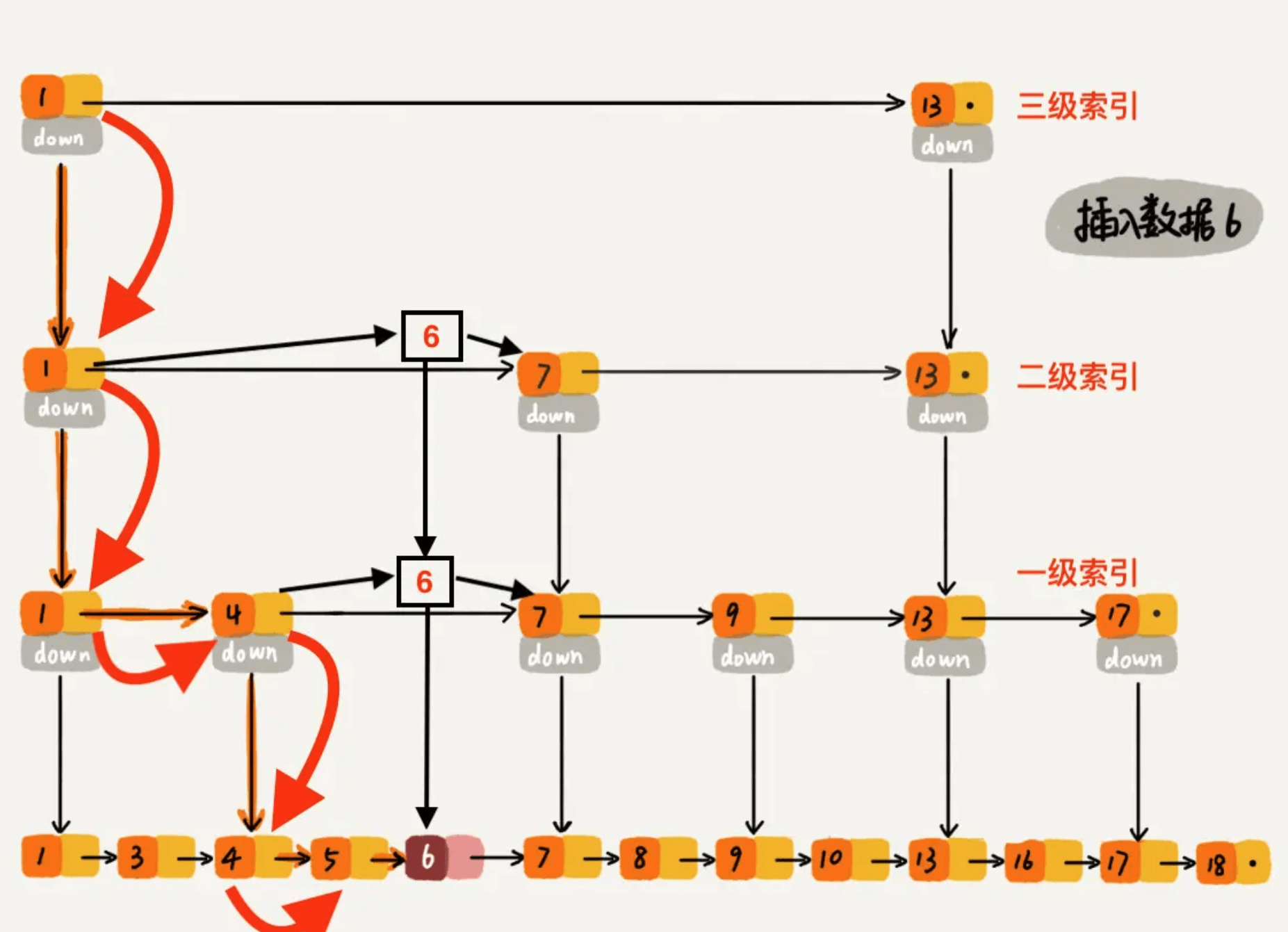
整个插入过程的路径与查找元素路径类似, 每层索引中插入元素的时间复杂度 O(1),所以整个插入的时间复杂度是 O(logn)。
四、跳表删除数据
跳表中,删除元素的时间复杂度是多少呢?
删除元素的过程跟查找元素的过程类似,只不过在查找的路径上如果发现了要删除的元素 x,则执行删除操作。跳表中,每一层索引其实都是一个有序的单链表,单链表删除元素的时间复杂度为 O(1),索引层数为 logn 表示最多需要删除 logn 个元素,所以删除元素的总时间包含 查找元素的时间 加 删除 logn个元素的时间 为 O(logn) + O(logn) = 2 O(logn),忽略常数部分,删除元素的时间复杂度为 O(logn)。
五、总结
跳表是可以实现二分查找的有序链表;
每个元素插入时随机生成它的level;
最底层包含所有的元素;
如果一个元素出现在level(x),那么它肯定出现在x以下的level中;
每个索引节点包含两个指针,一个向下,一个向右;(笔记目前看过的各种跳表源码实现包括Redis 的zset 都没有向下的指针,那怎么从二级索引跳到一级索引呢?留个悬念,看源码吧,文末有跳表实现源码)
跳表查询、插入、删除的时间复杂度为O(log n),与平衡二叉树接近;
六、Java实现跳表
1 | package 算法.skipList; |
工业上其他使用跳表的场景
在博客上从来没有见过有同学讲述 HBase MemStore 的数据结构,其实 HBase MemStore 内部存储数据就使用的跳表。为什么呢?HBase 属于 LSM Tree 结构的数据库,LSM Tree 结构的数据库有个特点,实时写入的数据先写入到内存,内存达到阈值往磁盘 flush 的时候,会生成类似于 StoreFile 的有序文件,而跳表恰好就是天然有序的,所以在 flush 的时候效率很高,而且跳表查找、插入、删除性能都很高,这应该是 HBase MemStore 内部存储数据使用跳表的原因之一。HBase 使用的是 java.util.concurrent 下的 ConcurrentSkipListMap()。
Google 开源的 key/value 存储引擎 LevelDB 以及 Facebook 基于 LevelDB 优化的 RocksDB 都是 LSM Tree 结构的数据库,他们内部的 MemTable 都是使用了跳表这种数据结构。
链接:https://baijiahao.baidu.com/s?id=1710441201075985657&wfr=spider&for=pc
原文链接:https://blog.csdn.net/weixin_45480785/article/details/116293416
链接:https://www.jianshu.com/p/9d8296562806
四、LSM-Tree
LSM-tree(Log-structured merge-tree),因其独特的数据组织方式(Log-structured)和需要在后台不断合并(Merge)的维护方式而得名。又因为顺序写(Sequentially Write)的模式,而取代B+ Tree(更新时会产生慢出2个数量级的随机写),被广泛应用于写密集型(Write-intensive)的数据库。
LSM-tree的思想和名字,直接来源于1992年发表的_Log Structured File System(LSF)_。LSF的作者之一John Ousterhout当时还在Berkeley,21年后,他作为Stanford的教授和他的PhD 学生Diego Ongaro完成了_Raft_论文,在分布式共识(Consensus)领域开辟了新天地。
1996年,LSM-tree的论文由Patrick O’Neil等人正式发表。2006年,Google的Bigtable问世(带来了memtable, SSTable的概念),在催生了HBase、Cassandra等NoSQL开源项目的同时,也让LSM-tree真正大规模地进入工业界的视线。
2011年,Google工程师Sanjay Ghemawat和Jeff Dean开源了LevelDB。2013年,Facebook在LevelDB的基础上开发了RocksDB。自此,LSM-tree成为存储引擎(Storage Engine)中不可忽视的一种数据结构,在新硬件、新数据负载不断出现的今天,仍在不断地被研究和扩展。
LSM Tree(log-structured merge-tree)是一种文件组织结构的数据结构,目前在不少数据库中都有使用到,如SQLite、LevelDB、HBase在Mongodb中也有一个LSM引擎;
在传统的关系型数据库中使用的是B-/B+ tree作为索引的数据结构,B tree的查询性能很高,为O(log n)复杂度,但其写性能并达不到O(log n),而在传统数据库中每次插入、删除数据都要更新索引,每次更新索引都会有一次磁盘IO,频繁写时其性能较低;
LSM Tree查询性能达不到理论的**O(log n)**,但效率并不慢,且其避免了频繁写时的磁盘IO,使得非常适用于KV与日志型数据库;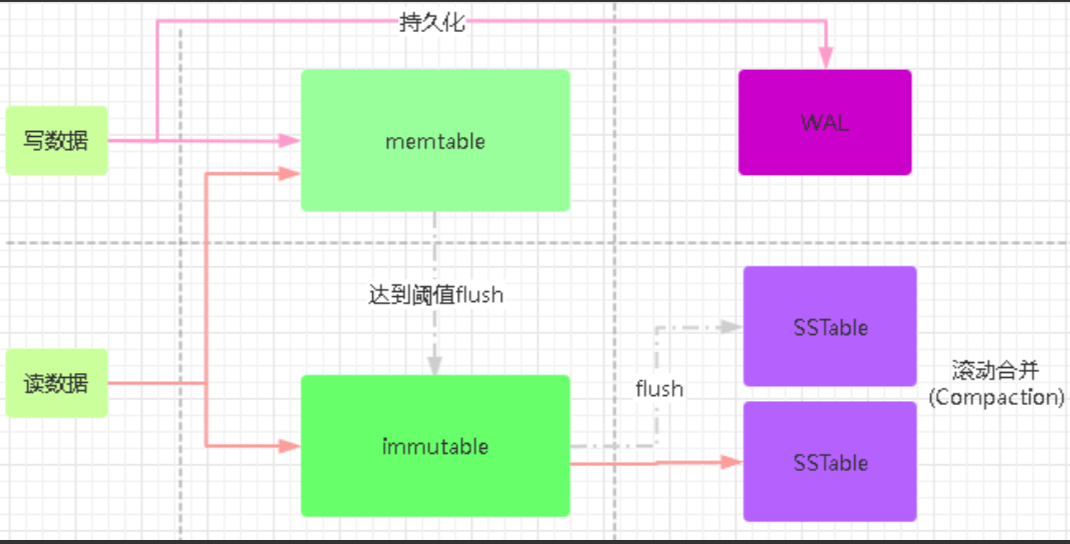
什么是LSM-Tree
LSM-Tree全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘的数据结构,其核心思想是充分了利用了,磁盘批量的顺序写要远比随机写性能高出很多,
围绕这一原理进行设计和优化,以此让写性能达到最优,正如我们普通的Log的写入方式,这种结构的写入,全部都是以Append的模式追加,不存在删除和修改。当然有得就有舍,这种结构虽然大大提升了数据的写入能力,却是以牺牲部分读取性能为代价,故此这种结构通常适合于写多读少的场景。故LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。这里面最典型的例子就属于Kakfa了,把磁盘顺序写发挥到了极致,故而在大数据领域成为了互联网公司标配的分布式消息中间件组件。
虽然这种结构的写非常简单高效,但其缺点是对读取特别是随机读很不友好,这也是为什么日志通常用在下面的两种简单的场景:
(1) 数据是被整体访问的,大多数数据库的WAL(write ahead log)也称预写log,包括mysql的Binlog等
(2) 数据是通过文件的偏移量offset访问的,比如Kafka。
想要支持更复杂和高效的读取,比如按key查询和按range查询,就得需要做一步的设计,这也是LSM-Tree结构,除了利用磁盘顺序写之外,还划分了内存+磁盘多层的合并结构的原因,正是基于这种结构再加上不同的优化实现,才造就了在这之上的各种独具特点的NoSQL数据库,如Hbase,Cassandra,Leveldb,RocksDB,MongoDB,TiDB等。
LSM-Tree 合并思想
LSM 树由两个或以上的存储结构组成,比如在论文中为了方便说明使用了最简单的两个存储结构。一个存储结构常驻内存中,称为 C0 tree ,具体可以是任何方便健值查找的数据结构,比如红黑树、 map 之类,甚至可以是跳表。另外一个存储结构常驻在硬盘中,称为 C1 tree ,具体结构类似 B 树。 C1 所有节点都是 100% 满的,节点的大小为磁盘块大小。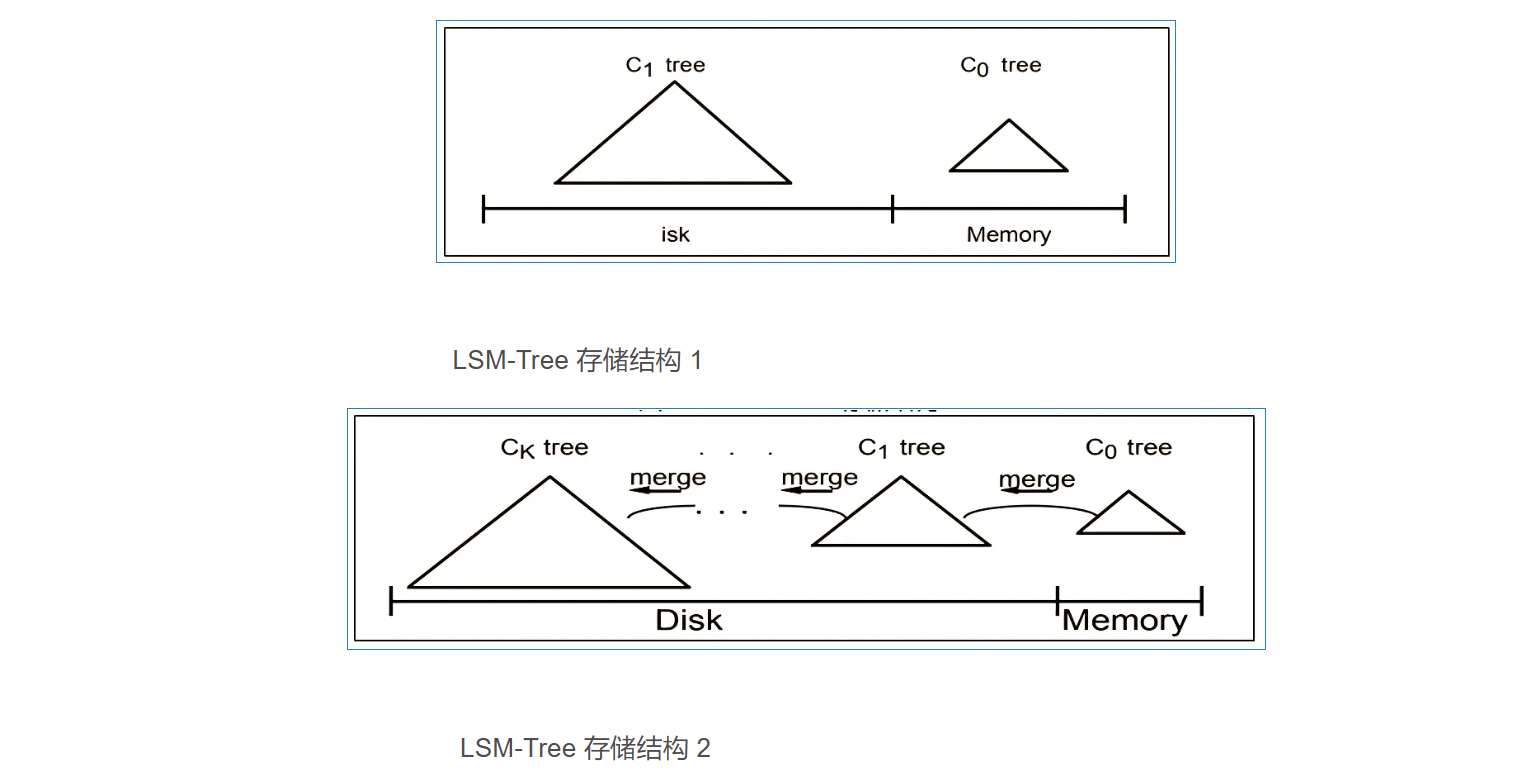
如上图所示,数据库采用了基于 LSM Tree 结构作为数据库的存储引擎,数据被分为基线数据( SSTable )和增量数据( MemTable )两部分,基线数据被保存在磁盘中,当需要读取的时候会被加载到数据库的缓存中,当数据被不断插入(或者修改时)在内存中缓存增量数据,当增量数据达到一定阀值时,就把增量数据刷新到磁盘上,当磁盘上的增量数据达到一定阀值时再把磁盘上的增量数据和基线数据进行合并。这个本身是 LSM 的核心设计思想,非常朴素,就是将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,从而大幅度提升性能。关于树的节点数据结构,不同数据库在基于 LSM-Tree 思想实现具体存储引擎的时候,可以根据自己的特点去定义。
LSM-Tree WAL
谈及 LSM ( Log Structured Merge Tree )树存储引擎,从字面意思上,其实我们基本能看到两层意思,第一个是 Merge ,就是我们上一节说到的合并思想;另外一个就是 Log ,就是我们接下来要说的 WAL 文件,从下面展示的基于 LSM 存储引擎的写的流程当中,我们可以看到 WAL 就是数据库的一个日志文件。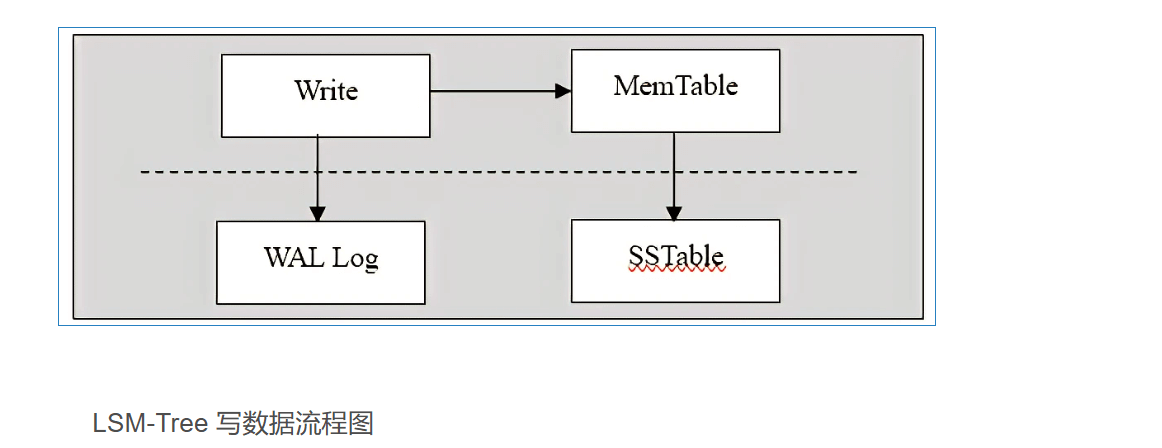
当插入一条数据时,数据先顺序写入磁盘保存的 WAL 文件中,之后插入到内存中的 Memtable 当中, Memtable 实际上保存的数据结构就是我们所述的内存当中的小树。这样就保证了数据的持久化,即使因为故障宕机,虽然内存里面的数据已经丢失,但是依然可以通过日志信息恢复当初内存里面的数据信息,并且都是顺序写,速度非常快。当 memtable 写入文件 SSTable 后,这个 log 文件的内容就不再需要了。而新的 memtable 会有新的 log 文件对应。
SSTable 和 LSM-Tree
提到LSM-Tree这种结构,就得提一下LevelDB这个存储引擎,我们知道Bigtable是谷歌开源的一篇论文,很难接触到它的源代码实现。如果说Bigtable是分布式闭源的一个高性能的KV系统,那么LevelDB就是这个KV系统开源的单机版实现,最为重要的是LevelDB是由Bigtable的原作者 Jeff Dean 和 Sanjay Ghemawat 共同完成,可以说高度复刻了Bigtable 论文中对于其实现的描述。
SSTable是一种拥有持久化,有序且不可变的的键值存储结构,它的key和value都是任意的字节数组,并且了提供了按指定key查找和指定范围的key区间迭代遍历的功能。SSTable内部包含了一系列可配置大小的Block块,典型的大小是64KB,关于这些Block块的index存储在SSTable的尾部,用于帮助快速查找特定的Block。当一个SSTable被打开的时候,index会被加载到内存,然后根据key在内存index里面进行一个二分查找,查到该key对应的磁盘的offset之后,然后去磁盘把响应的块数据读取出来。当然如果内存足够大的话,可以直接把SSTable直接通过MMap的技术映射到内存中,从而提供更快的查找。
SSTable 在后台是要经过不断地排序合并,文件随着层次的加深,其大小也逐步变大。同时它也是可以启用压缩功能的,并且这种压缩不是将整个 SSTable 一起压缩,而是根据 locality 将数据分组,每个组分别压缩,这样的好处当读取数据的时候,我们不需要解压缩整个文件而是解压缩部分 Group 就可以读取。如图下图所示的情况, leve0 的 SSTable 达到数据量的阀值之后,会经过排序合并形成 Level1 的 SSTable , Level1 的 SSTable 达到阀值之后,会经过排序合并成为 Level2 的 SSTable 文件。
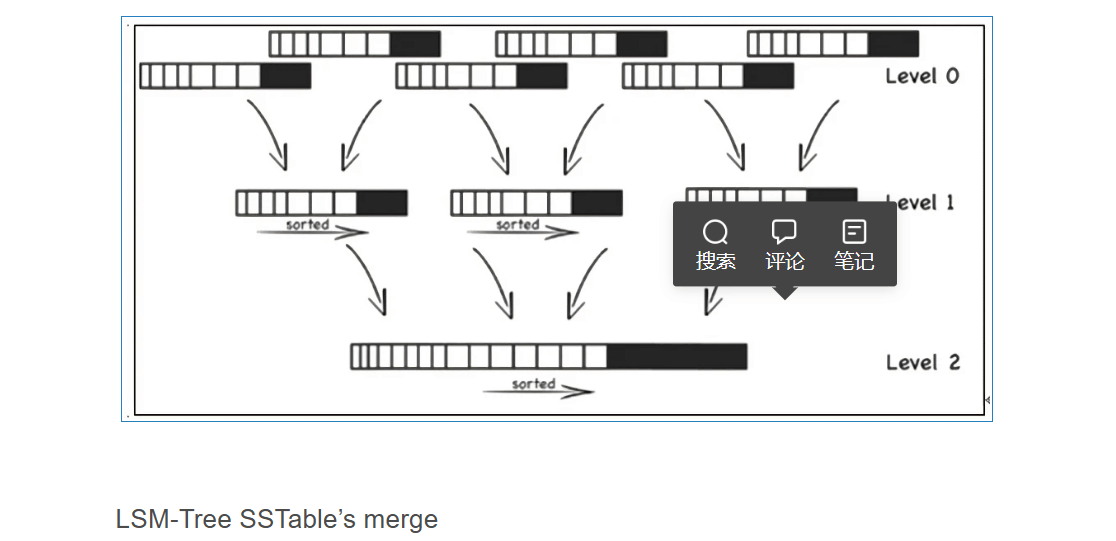
以上图中所示的文件合并过程是一个排序合并的过程,因此每一层都包含大量 SSTable 文件,但是键值值范围不重复,这样查询操作只需要查询这一层的一个 SSTable 文件即可。
关于LSM-Tree的读写原理
在LSM-Tree里,SSTable有一份在内存里面,其他的多级在磁盘上,如下图是一份完整的LSM-Tree图示: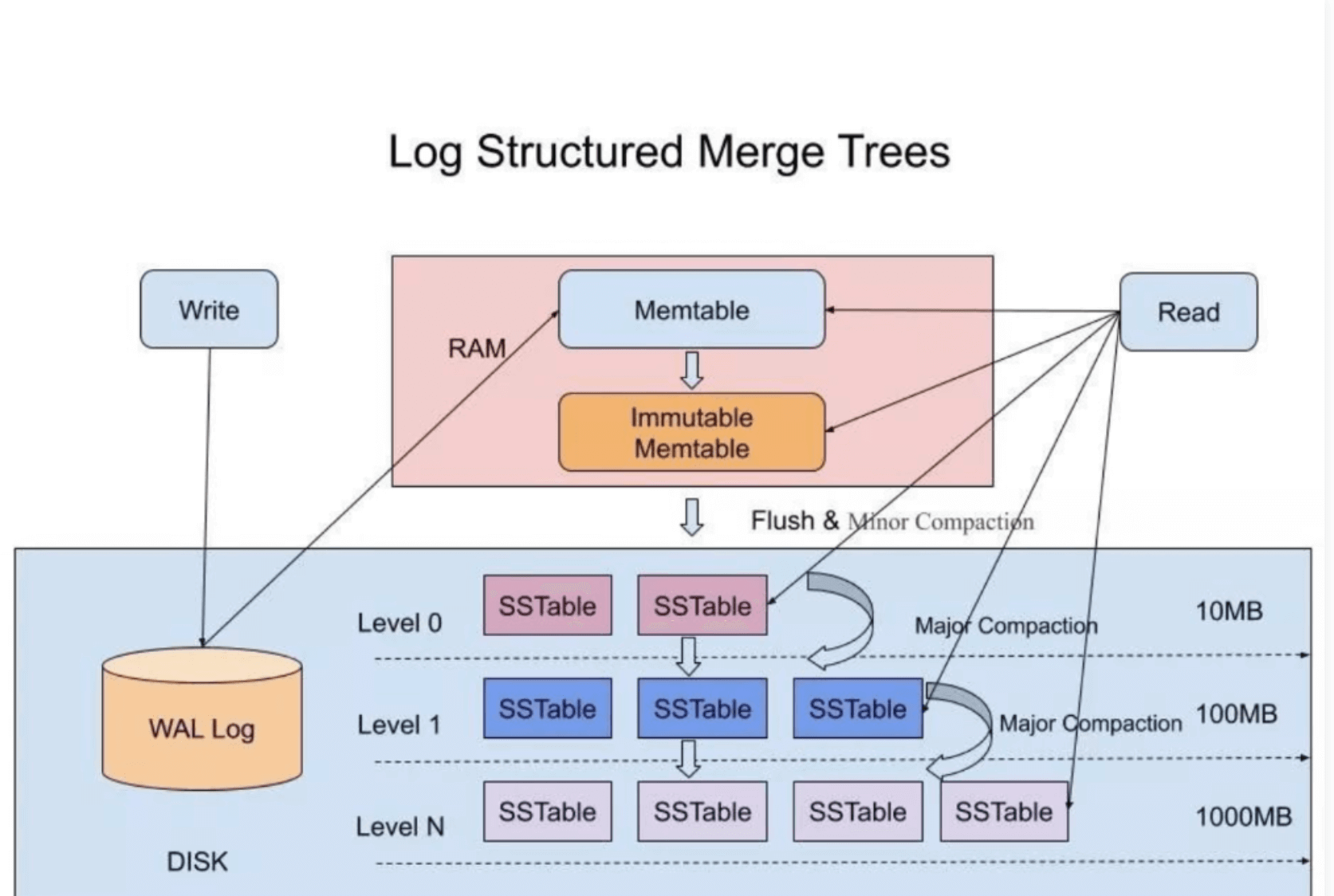
LSM-Tree写数据的过程
当收到一个写请求时,会先把该条数据记录在WAL Log里面,用作故障恢复。
当写完WAL Log后,会把该条数据写入内存的SSTable里面(删除是墓碑标记,更新是新记录一条的数据),也称Memtable。注意为了维持有序性在内存里面可以采用红黑树或者跳跃表相关的数据结构。
当Memtable超过一定的大小后,会在内存里面冻结,变成不可变的Memtable,同时为了不阻塞写操作需要新生成一个Memtable继续提供服务。
把内存里面不可变的Memtable给dump到到硬盘上的SSTable层中,此步骤也称为Minor Compaction,这里需要注意在L0层的SSTable是没有进行合并的,所以这里的key range在多个SSTable中可能会出现重叠,在层数大于0层之后的SSTable,不存在重叠key。
当每层的磁盘上的SSTable的体积超过一定的大小或者个数,也会周期的进行合并。此步骤也称为Major Compaction,这个阶段会真正 的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间,注意由于SSTable都是有序的,我们可以直接采用merge sort进行高效合并。
LSM-Tree读数据的过程
- 当收到一个读请求的时候,会直接先在内存里面查询,如果查询到就返回。
- 如果没有查询到就会依次下沉,知道把所有的Level层查询一遍得到最终结果。
思考查询步骤,我们会发现如果SSTable的分层越多,那么最坏的情况下要把所有的分层扫描一遍,对于这种情况肯定是需要优化的,如何优化?在 Bigtable 论文中提出了几种方式:
(1)、压缩
SSTable 是可以启用压缩功能的,并且这种压缩不是将整个 SSTable 一起压缩,而是根据 locality 将数据分组,每个组分别压缩,这样的好处当读取数据的时候,我们不需要解压缩整个文件而是解压缩部分 Group 就可以读取。
(2)、缓存
因为SSTable在写入磁盘后,除了Compaction之外,是不会变化的,所以我可以将Scan的Block进行缓存,从而提高检索的效率
(3)、索引,Bloom filters
正常情况下,一个读操作是需要读取所有的 SSTable 将结果合并后返回的,但是对于某些 key 而言,有些 SSTable 是根本不包含对应数据的,因此,我们可以对每一个 SSTable 添加 Bloom Filter,因为布隆过滤器在判断一个SSTable不存在某个key的时候,那么就一定不会存在,利用这个特性可以减少不必要的磁盘扫描。
(4)、合并
这个在前面的写入流程中已经介绍过,通过定期合并瘦身, 可以有效的清除无效数据,缩短读取路径,提高磁盘利用空间。但Compaction操作是非常消耗CPU和磁盘IO的,尤其是在业务高峰期,如果发生了Major Compaction,则会降低整个系统的吞吐量,这也是一些NoSQL数据库,比如Hbase里面常常会禁用Major Compaction,并在凌晨业务低峰期进行合并的原因。
最后有的同学可能会问道,为什么LSM不直接顺序写入磁盘,而是需要在内存中缓冲一下? 这个问题其实很容易解答,单条写的性能肯定没有批量写来的块,这个原理其实在Kafka里面也是一样的,虽然kafka给我们的感觉是写入后就落地,但其实并不是,本身是 可以根据条数或者时间比如200ms刷入磁盘一次,这样能大大提升写入效率。此外在LSM中,在磁盘缓冲的另一个好处是,针对新增的数据,可以直接查询返回,能够避免一定的IO操作。
LSM-Tree 数据修改过程
LSM-Tree 存储引擎的更新过程其实并不存在,它不会像 B 树存储引擎那样,先经过检索过程,然后再进行修改。它的更新操作是通过追加数据来间接实现,也就是说更新最终转换为追加一个新的数据。只是在读取的时候,会从 Level0 层的 SSTable 文件开始查找数据,数据在低层的 SSTable 文件中必然比高层的文件中要新,所以总能读取到最新的那条数据。也就是说此时在整个 LSM Tree 中可能会同时存在多个 key 值相同的数据,只有在之后合并 SSTable 文件的时候,才会将旧的值删除。
LSM-Tree 数据删除过程
LSM-Tree 存储引擎的对数据的删除过程与追加数据的过程基本一样,区别在于追加数据的时候,是有具体的数据值的,而删除的时候,追加的数据值是删除标记。同样在读取的时候,会从 Level0 层的 SSTable 文件开始查找数据,数据在低层的 SSTable 文件中必然比高层的文件中要新,所以如果有删除操作,那么一定会最先读到带删除标记的那条数据。后期合并 SSTable 文件的时候,才会把数据删除。
B+Tree VS LSM-Tree
传统关系型数据采用的底层数据结构是B+树,那么同样是面向磁盘存储的数据结构LSM-Tree相比B+树有什么异同之处呢?
LSM-Tree的设计思路是,将数据拆分为几百M大小的Segments,并是顺序写入。
B+Tree则是将数据拆分为固定大小的Block或Page, 一般是4KB大小,和磁盘一个扇区的大小对应,Page是读写的最小单位。
在数据的更新和删除方面,B+Tree可以做到原地更新和删除,这种方式对数据库事务支持更加友好,因为一个key只会出现一个Page页里面,但由于LSM-Tree只能追加写,并且在L0层key的rang会重叠,所以对事务支持较弱,只能在Segment Compaction的时候进行真正地更新和删除。
因此LSM-Tree的优点是支持高吞吐的写(可认为是O(1)),这个特点在分布式系统上更为看重,当然针对读取普通的LSM-Tree结构,读取是O(N)的复杂度,在使用索引或者缓存优化后的也可以达到O(logN)的复杂度。
而B+tree的优点是支持高效的读(稳定的OlogN),但是在大规模的写请求下(复杂度O(LogN)),效率会变得比较低,因为随着insert的操作,为了维护B+树结构,节点会不断的分裂和合并。操作磁盘的随机读写概率会变大,故导致性能降低。
还有一点需要提到的是基于LSM-Tree分层存储能够做到写的高吞吐,带来的副作用是整个系统必须频繁的进行compaction,写入量越大,Compaction的过程越频繁。而compaction是一个compare & merge的过程,非常消耗CPU和存储IO,在高吞吐的写入情形下,大量的compaction操作占用大量系统资源,必然带来整个系统性能断崖式下跌,对应用系统产生巨大影响,当然我们可以禁用自动Major Compaction,在每天系统低峰期定期触发合并,来避免这个问题。
阿里为了优化这个问题,在X-DB引入了异构硬件设备FPGA来代替CPU完成compaction操作,使系统整体性能维持在高水位并避免抖动,是存储引擎得以服务业务苛刻要求的关键。
LSM Tree的用武之地
elasticsearch搜索引擎中有用到LSM-Tree
clickHouse中有用到LSM-Tree
总结
本文主要介绍了LSM-Tree的相关内容,简单的说,其牺牲了部分读取的性能,通过批量顺序写来换取了高吞吐的写性能,这种特性在大数据领域得到充分了体现,最直接的例子就各种NoSQL在大数据领域的应用,学习和了解LSM-Tree的结构将有助于我们更加深入的去理解相关NoSQL数据库的实现原理,掌握隐藏在这些框架下面的核心知识。
原文链接:https://blog.csdn.net/star1210644725/article/details/120384972

